Dell VPLEX Deploy Achievement Questions and Answers
What is the default subnet mask value for management server network 128.221.252.0?
Options:
255.255.255.248
255.255.255.192
255.255.255.128
255.255.255.224
Answer:
AExplanation:
The default subnet mask for a management server network, specifically for the network 128.221.252.0, is typically a subnet mask that allows for a small number of hosts, as management networks do not usually require a large number of IP addresses.
Subnet Mask Purpose: A subnet mask is used in IP networking to divide the IP address into a network and host identifier. The default subnet mask for a particular network depends on the class and configuration of the network1.
Management Server Network: For a management server network like 128.221.252.0, a common default subnet mask is 255.255.255.248. This subnet mask allows for up to 6 usable IP addresses, which is generally sufficient for management purposes1.
Network Configuration: The choice of subnet mask can affect the number of hosts that can be accommodated within a network. A subnet mask of 255.255.255.248 indicates a very small network, often used for specialized network segments such as management interfaces1.
Dell VPLEX Configuration: In the context of Dell VPLEX Deploy Achievement, the management server network would be configured with a subnet mask that supports the network architecture and design best practices as outlined in Dell’s documentation1.
Best Practices: It is important to follow the recommended settings and configurations provided in the Dell VPLEX Deploy Achievement documents to ensure proper network segmentation, security, and performance1.
In summary, the default subnet mask value for a management server network like 128.221.252.0 is typically 255.255.255.248, which aligns with the standard practices for configuring management networks in a Dell VPLEX environment.
A VPLEX Metro cluster is being installed for a company that is planning to create distributed volumes with 200 TB of storage. Based on this requirement, and consistent with
EMC best practices, what should be the minimum size for logging volumes at each cluster?
Options:
10 GB
. 12.5 GB
16.5 GB
20 GB
Answer:
AExplanation:
When configuring a VPLEX Metro cluster, especially for a company planning to create distributed volumes with a large amount of storage like 200 TB, it is essential to adhere to EMC best practices for the size of logging volumes.
Purpose of Logging Volumes: Logging volumes in VPLEX are used to store write logs that ensure data integrity and consistency across distributed volumes. These logs play a critical role during recovery processes1.
Size Considerations: The size of the logging volumes should be proportional to the amount of active data being written to ensure that all write operations are captured in the logs. For 200 TB of distributed storage, a minimum size of 10 GB for each logging volume is recommended to handle the logging requirements1.
Configuration: The logging volumes should be configured on each cluster to provide redundancy and high availability. This means that both clusters in a VPLEX Metro configuration should have logging volumes of at least the minimum recommended size1.
Best Practices: EMC best practices suggest that the logging volume should be sized appropriately to support the operational workload and to ensure that there is sufficient space to capture all write operations without any loss of data1.
Verification and Monitoring: After setting up the logging volumes, it is important to monitor their utilization to ensure they are functioning correctly and to adjust their size if necessary based on the actual workload1.
In summary, consistent with EMC best practices, the minimum size for logging volumes at each cluster in a VPLEX Metro cluster being installed for creating distributed volumes with 200 TB of storage should be 10 GB. This size ensures that the logging volumes can adequately support the write logging requirements for the amount of storage being used.
=========================
When are the front-end ports enabled during a VPLEX installation?
Options:
Before launching the VPLEX EZ-Setup wizard
Before creating the metadata volumes and backup
After exposing the storage to the hosts
After creating the metadata volumes and backup
Answer:
DExplanation:
During a VPLEX installation, the front-end ports are enabled after the metadata volumes and backup have been created. This sequence ensures that the system’s metadata, which is crucial for the operation of VPLEX, is secured before the storage is exposed to the hosts.
Metadata Volumes Creation: The first step in the VPLEX installation process involves creating metadata volumes. These volumes store configuration and operational data necessary for VPLEX to manage the virtualized storage environment1.
Metadata Backup: After the metadata volumes are created, it is essential to back up this data. The backup serves as a safeguard against data loss and is a critical step before enabling the front-end ports1.
Enabling Front-End Ports: Once the metadata is secured, the front-end ports can be enabled. These ports are used for host connectivity, allowing hosts to access the virtual volumes presented by VPLEX1.
Exposing Storage to Hosts: With the front-end ports enabled, the storage can then be exposed to the hosts. This step involves presenting the virtual volumes to the hosts through the front-end ports1.
Final Configuration: The final configuration steps may include zoning, LUN masking, and setting up host access to the VPLEX virtual volumes. These steps are completed after the front-end ports are enabled and the storage is exposed1.
In summary, the front-end ports are enabled during a VPLEX installation after the metadata volumes and backup have been created, which is reflected in option D. This ensures that the system metadata is protected and available before the storage is made accessible to the hosts.
What is a key benefit of VPLEX continuous availability?
Options:
No need for backups
Eliminates data corruption
No complex failover
Enables automatic LUN recovery
Answer:
CExplanation:
One of the key benefits of VPLEX continuous availability is the elimination of complex failover procedures. VPLEX provides a unique implementation of distributed cache coherency, which allows the same data to be read/write accessible across two storage systems at the same time. This ensures uptime for business-critical applications and enables seamless data mobility across host arrays without host disruption1.
Continuous Application Availability: VPLEX maximizes the returns on investments in infrastructure by providing continuous availability to workloads, ensuring that applications remain up and running even in the face of disasters1.
Operational Agility: VPLEX offers operational agility to match the infrastructure to changing business needs, allowing for rapid response to business and technology changes while maximizing asset utilization across active-active data centers1.
Seamless Workload Mobility: The seamless workload mobility feature of VPLEX creates a flexible storage architecture that makes data and workload mobility effortless, contributing to the overall operational efficiency2.
Non-Disruptive Technology Refresh: VPLEX supports non-disruptive technology refresh, enabling data center modernization efforts through online technology refresh without impacting business operations2.
Active-Active Data Centers: VPLEX Metro allows applications to simultaneously read/write on both sites, increasing resource utilization and providing a true Recovery Time Objective (RTO) and Recovery Point Objective (RPO) of zero2.
In summary, the elimination of complex failover is a key benefit of VPLEX continuous availability, providing businesses with the assurance that their critical applications will continue to operate smoothly even during disruptions.
Connectivity has been restored after a WAN outage. The storage administrator of a VPLEX VS6 now wants to verify management connectivity between MMCS-A on Cluster-1
and MMCS-A on Cluster-2.
Which command can the administrator run to determine if the remote management IP is reachable?
Options:
connectivity validate-wan-com
11 /engines/ ** /ports
sudo /usr/sbin/ipsec statusall
vpn status
Answer:
DExplanation:
After a WAN outage, to verify management connectivity between MMCS-A on Cluster-1 and MMCS-A on Cluster-2, the storage administrator should use the vpn status command. This command checks the status of the VPN tunnels that facilitate secure communication between the management servers and the Cluster Witness Server.
Command Execution: The administrator should execute the vpn status command in the VPLEX CLI. This command will provide information about the state of the VPN tunnels1.
Interpreting Results: The output from the vpn status command will indicate whether the IPsec VPN tunnels are up and if the remote management servers are reachable. It will show the status of connectivity with both the management servers and the Cluster Witness Server1.
VPN Tunnel Status: The command will show the status of the VPN tunnel between the management servers, which is crucial for the clusters to communicate and operate as a metro system1.
Cluster Witness Server Connectivity: Additionally, the command will verify the VPN status between the management server and the Cluster Witness Server, ensuring that the witness can monitor the health and status of the clusters1.
Troubleshooting: If the vpn status command indicates that the remote management IP is not reachable, further troubleshooting will be required to establish connectivity. This may involve checking network configurations, firewall settings, and ensuring that the VPN services are running properly1.
In summary, the vpn status command is used to determine if the remote management IP is reachable, providing a quick and effective way to verify management connectivity between VPLEX clusters after a WAN outage.
What is the correct order of steps to migrate from an old array to a new one without disruption using VPLEX?

Options:
Answer:
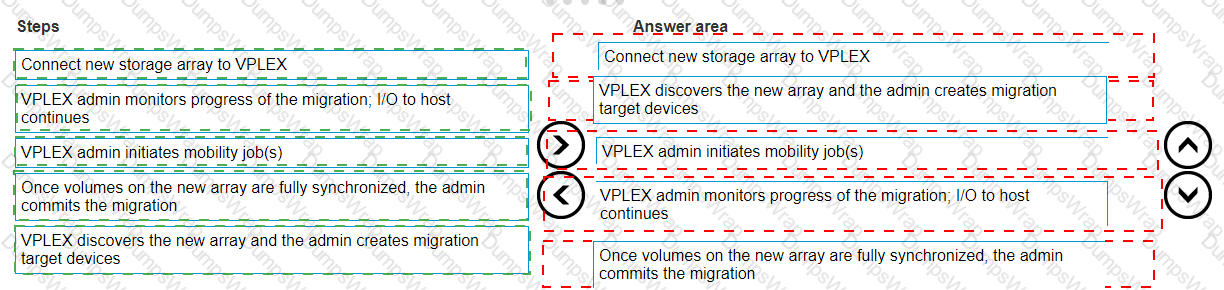
Explanation:


The correct order of steps to migrate from an old array to a new one without disruption using VPLEX is as follows:
Connect the new storage array to VPLEX.
VPLEX discovers the new array, and the admin creates migration target devices.
The VPLEX admin initiates mobility job(s).
VPLEX admin monitors the progress of the migration; I/O to the host continues.
Once volumes on the new array are fully synchronized, the admin commits the migration.
Connect New Storage Array: The first step involves physically connecting the new storage array to the VPLEX system and ensuring proper connectivity1.
Discovery and Device Creation: VPLEX then discovers the new array. The administrator uses the VPLEX management interface to create the target devices that will receive the data from the old array1.
Initiate Mobility Jobs: The administrator initiates mobility jobs using the VPLEX CLI or management interface. These jobs handle the data transfer from the old array’s devices to the new array’s devices1.
Monitor Migration Progress: While the mobility jobs are running, the administrator monitors the progress. During this time, the host continues to perform I/O operations without disruption1.
Commit Migration: After the data has been fully synchronized to the new array, the administrator commits the migration. This finalizes the transfer and allows the host to use the new array’s devices as if they were the original ones1.
This process ensures a smooth and non-disruptive migration from an old storage array to a new one using VPLEX, maintaining continuous availability of applications and data.
What are the requirements to upgrade a VPLEX from VS2 to VS6?
Options:
GeoSynchrony 6.0 minimum
Both VS2 and VS6 at same code level
Same number of engines
WWN zoning
GeoSynchrony 5.0 minimum
Both VS2 and VS6 at same code level
Same number of engines
WWN zoning
GeoSynchrony 6.0 minimum
Both VS2 and VS6 at same code level
Same number of engines
WWN zoning and temporary FC Local COM I/O modules in VS2
GeoSynchrony 6.0 minimum
Both VS2 and VS6 at same code level
Same number of engines
WWN zoning and temporary FC Local COM I/O modules in VS6
Answer:
AExplanation:
Upgrading a VPLEX from VS2 to VS6 hardware involves several critical requirements to ensure a successful and non-disruptive process:
GeoSynchrony Version: The system must be running at least GeoSynchrony 6.0. This is the software that orchestrates operations across the VPLEX infrastructure and ensures compatibility between different hardware generations1.
Code Level Consistency: Both the VS2 and VS6 platforms must be operating at the same software code level. This uniformity is crucial to prevent any incompatibility issues during the upgrade process1.
Engine Count: The number of engines in the existing VS2 setup must match the number of engines in the VS6 configuration. This alignment is necessary to maintain performance and capacity expectations post-upgrade1.
WWN Zoning: Proper WWN (World Wide Name) zoning must be in place. WWN zoning is a method of isolating network traffic to ensure that devices within a Fibre Channel network can only communicate with each other if they are in the same zone1.
Upgrade Process: The upgrade process typically involves replacing the VS2 hardware with VS6 components. This hardware swap should be done in a manner that does not disrupt the ongoing operations and services1.
Post-Upgrade Verification: After the hardware upgrade, it’s essential to verify that all systems are functioning correctly. This includes checking the status of the front-end and back-end ports, as well as the health of the virtual volumes1.
Documentation and Support: Detailed procedures for the upgrade process can be found in the SolVe Desktop Procedure Generator, which provides step-by-step instructions for upgrading cluster hardware from VS2 to VS61.
In summary, the requirements for upgrading a VPLEX from VS2 to VS6 include running GeoSynchrony 6.0 or higher, ensuring both platforms are at the same code level, matching the number of engines, and having proper WWN zoning in place.
What is an EMC best practice for connecting VPLEX to back-end arrays?
Options:
One multiple switch fabric should be used for each VPLEX engine
Back-end connections should be distributed across one director
Each VPLEX director should have four active paths to every back-end array storage volume
Two active paths per VPLEX engine to any storage volume is optimal
Answer:
CExplanation:
EMC recommends specific best practices for connecting VPLEX to back-end storage arrays to ensure high availability and optimal performance. One of these best practices is that each VPLEX director should have four active paths to every back-end array storage volume.
Multiple Paths: Having multiple active paths from each VPLEX director to the storage volumes ensures that there is no single point of failure. If one path fails, the other paths can continue to provide connectivity1.
Load Balancing: Multiple paths also allow for load balancing of I/O operations across the different paths, which can improve performance and reduce the risk of bottlenecks1.
Path Redundancy: Path redundancy is crucial for maintaining continuous availability, especially in environments where the VPLEX is used for mission-critical applications1.
Configuration: The configuration of the paths should be done in accordance with EMC’s best practices, which include proper zoning and masking in the SAN environment1.
Documentation: Detailed guidelines and best practices for VPLEX SAN connectivity, including back-end array connections, are available in EMC’s documentation, which provides comprehensive instructions for setting up and managing these connections1.
In summary, EMC’s best practice for connecting VPLEX to back-end arrays is to ensure that each VPLEX director has four active paths to every back-end array storage volume. This setup provides the necessary redundancy and performance for a robust and reliable storage environment.
=========================
Which command is used to display available statistics for monitoring VPLEX?
Options:
monitor collect
monitor create
monitor add-sink
monitor stat-list
Answer:
DExplanation:
The command used to display available statistics for monitoring VPLEX is monitor stat-list. This command provides a list of all the statistics that can be monitored on the VPLEX system.
Command Usage: The monitor stat-list command is executed in the VPLEX CLI (Command Line Interface). When run, it will display a list of all the statistics that are available for monitoring1.
Monitoring Statistics: The statistics available for monitoring can include various performance metrics such as IOPS (Input/Output Operations Per Second), throughput, and latency. These metrics are crucial for assessing the health and performance of the VPLEX system1.
Custom Monitors: In addition to the default system monitors, custom monitors can be created to track specific data. The monitor stat-list command helps in identifying which statistics can be included in these custom monitors1.
Performance Analysis: By using the monitor stat-list command, administrators can determine which statistics are relevant for their performance analysis and can then create monitors to track those specific metrics1.
Documentation Reference: For more information on the usage of the monitor stat-list command and other monitoring commands, administrators should refer to the VPLEX CLI and Administration Guides for the code level the VPLEX is running1.
In summary, the monitor stat-list command is used to display the available statistics for monitoring VPLEX, providing administrators with the information needed to set up and manage performance monitoring on the system.
VPLEX Metro has been added to an existing HP OpenView network monitoring environment. The VPLEX SNMP agent and other integration information have been added to assist in the implementation. After VPLEX is added to SNMP monitoring, only the remote VPLEX cluster is reporting performance statistics.
What is the cause of this issue?
Options:
HP OpenView is running SNMP version 2C, which may cause reporting that does not contain the performance statistics.
TCP Port 443 is blocked at the local site's firewall.
Local VPLEX cluster management server has a misconfigured SNMP agent.
Local VPLEX Witness has a misconfigured SNMP agent.
Answer:
CExplanation:
When VPLEX Metro is added to an existing HP OpenView network monitoring environment and only the remote VPLEX cluster is reporting performance statistics, the likely cause is a misconfiguration of the SNMP agent on the local VPLEX cluster management server.
SNMP Agent Configuration: The SNMP (Simple Network Management Protocol) agent on the VPLEX management server must be correctly configured to communicate with the HP OpenView monitoring system. If the local cluster’s SNMP agent is misconfigured, it may not report performance statistics correctly1.
Troubleshooting Steps: To resolve this issue, the following steps should be taken:
Verify the SNMP configuration on the local VPLEX cluster management server.
Check for any discrepancies in the SNMP version, community strings, and allowed hosts between the local and remote clusters.
Ensure that the SNMP service is running and properly configured to send traps and fetches to the HP OpenView system1.
Firewall and Network Checks: Although TCP Port 443 is important for secure communications, it is not typically used for SNMP, which usually operates over UDP ports 161 and 162. Therefore, a blockage of TCP Port 443 would not directly affect SNMP reporting1.
HP OpenView Compatibility: While HP OpenView running SNMP version 2C could potentially cause issues with performance statistic reporting, if the remote cluster is reporting correctly, it suggests that the version of SNMP is not the issue in this case1.
VPLEX Witness Configuration: The VPLEX Witness is not directly involved in the reporting of performance statistics to HP OpenView, so a misconfiguration of the VPLEX Witness’s SNMP agent would not cause this specific issue1.
In summary, the cause of the issue where only the remote VPLEX cluster is reporting performance statistics to HP OpenView is likely due to a misconfigured SNMP agent on the local VPLEX cluster management server.

Which number in the exhibit highlights the Director-B back-end ports?
Options:
3
4
2
1
Answer:
BExplanation:
To identify the Director-B back-end ports in a VPLEX system, one must understand the standard port numbering and layout for VPLEX directors. Based on the information provided in the Dell community forum1, the back-end ports for Director-B can be identified by the following method:
Director Identification: Determine which director is Director-B. In a VPLEX system, directors are typically labeled as A or B, and each has a set of front-end and back-end ports1.
Port Numbering: The port numbering for a VPLEX director follows a specific pattern. For example, in a VS2 system, the back-end ports are typically numbered starting from 10 onwards, following the front-end ports which are numbered from 001.
Back-End Ports: Based on the standard VPLEX port numbering, the back-end ports for Director-B would be the second set of ports after the front-end ports. This is because the front-end ports are used for host connectivity, while the back-end ports connect to the storage arrays1.
Exhibit Analysis: In the exhibit provided, if the numbering follows the standard VPLEX layout, number 4 would highlight the Director-B back-end ports, assuming that number 3 highlights the front-end ports and the numbering continues sequentially1.
Verification: To verify the correct identification of the back-end ports, one can refer to the official Dell VPLEX documentation or use the VPLEX CLI to list the ports and their roles within the system1.
In summary, based on the standard layout and numbering of VPLEX systems, number 4 in the exhibit likely highlights the Director-B back-end ports. This identification is crucial for proper configuration and management of the VPLEX system.
A storage administrator has just been informed by their network team that a WAN outage has been restored.
How can the administrator verify that their VPLEX Metro WAN COM link is restored?
Options:
Run 11 /engines/ ** /sfps
Verify that all ports have good Rx and Tx power levels
Run vpn status
Verify that the peer IP is reachable
Run cluster summary
Verify that each cluster is listed under island 1
Run connectivity validate-local-com
Verify that all expected connectivity is present
Answer:
DExplanation:
To verify that the VPLEX Metro WAN COM link is restored, the storage administrator should run the connectivity validate-local-com command. This command checks the connectivity status of the local communication links within the VPLEX cluster.
Command Execution: The administrator should access the VPLEX CLI and execute the connectivity validate-local-com command. This will initiate a check of the local COM ports’ connectivity status1.
Interpreting Results: After running the command, the administrator should review the output to verify that all expected connectivity is present. The output will indicate whether each local COM port is communicating as expected1.
WAN COM Link: The WAN COM link is responsible for the communication between VPLEX clusters over a wide area network. Ensuring that the local COM links are operational is a prerequisite for the WAN COM link to function properly1.
Post-Outage Verification: Following a WAN outage, it’s crucial to confirm that the communication links are fully operational to maintain the high availability and data mobility features of VPLEX Metro1.
Best Practices: It is recommended to follow the Dell EMC VPLEX best practices for post-outage recovery, which include running the connectivity validate-local-com command to ensure that the system is ready to resume normal operations1.
In summary, the connectivity validate-local-com command is the correct procedure to verify that the VPLEX Metro WAN COM link is restored, as it checks and confirms the presence of all expected local communication link connectivity within the VPLEX cluster.
How many copies can RecoverPoint maintain in a MetroPoint topology?
Options:
8
6
4
5
Answer:
DExplanation:
"The MetroPoint topology can maintain up to five copies of data, including one remote copy and one local copy at each VPLEX site. It provides protection for each of the VPLEX Metro sites with continuous local replication via RecoverPoint"..
Which type of volume is subjected to high levels of I/O only during a WAN COM failure?
Options:
Distributed volume
Logging volume
Metadata volume
Virtual volume
Answer:
BExplanation:
Questions no: High I/O volume type during WAN COM failure
Verified Answer:B. Logging volume
Step by Step Comprehensive Detailed Explanation with References:During a WAN COM failure in a VPLEX Metro environment, logging volumes are subjected to high levels of I/O. This is because the logging volumes are used to store write logs that ensure data integrity and consistency across distributed volumes. These logs play a critical role during recovery processes, especially when there is a communication failure between clusters.
Role of Logging Volumes: Logging volumes in VPLEX are designed to capture write operations that cannot be immediately mirrored across the clusters due to network issues or WAN COM failures1.
WAN COM Failure: When a WAN COM failure occurs, the VPLEX system continues to write to the local logging volumes to ensure no data loss. Once the WAN COM link is restored, the logs are used to synchronize the data across the clusters1.
High I/O Levels: The high levels of I/O on the logging volumes during a WAN COM failure are due to the accumulation of write operations that need to be logged until the link is restored and the data can be synchronized1.
Recovery Process: After the WAN COM link is restored, the VPLEX system uses the data in the logging volumes to rebuild and synchronize the distributed volumes, ensuring data consistency and integrity1.
Best Practices: EMC best practices recommend monitoring the health and performance of logging volumes, especially during WAN COM failures, to ensure they can handle the increased I/O load and maintain system performance1.
In summary, logging volumes experience high levels of I/O only during a WAN COM failure as they are responsible for capturing and storing write operations until the communication between clusters can be re-established and data synchronization can occur.
What is a requirement for zoning FC WAN COM ports on a VPLEX Metro?
Options:
Each WAN COM port in the local cluster is zoned to all WAN COM ports in the remote cluster
Generate a command script with the IPComConfigWorksheet_v.x.x.zip tool
Each FC00 port in the local cluster is zoned to the FC01 port for each director in the remote cluster
Each FC00 port in the local cluster is zoned to the FC00 port for each director in the remote cluster
Answer:
AExplanation:
For zoning FC WAN COM ports on a VPLEX Metro, the requirement is that each WAN COM port in the local cluster must be zoned to all WAN COM ports in the remote cluster. This setup ensures that there is a redundant network capability where each director on one cluster communicates with all the directors on the other site, even in the event of a fabric or network failure1.
Zoning Configuration: The zoning needs to be fixed such that all A2-FC00 only see (are zoned with) remote A2-FC00 ports, and similarly for A2-FC01 with A2-FC01, and so on for all WAN COM ports1.
Redundant Network: This zoning configuration provides a redundant network capability, which is essential for maintaining communication between the two VPLEX clusters in a Metro configuration1.
Fabric Separation: The FC WAN COM ports will be connected to dual separate backbone fabrics or networks that span two sites, allowing for data flow between the two VPLEX clusters without requiring a merged fabric between the two sites1.
Best Practices: For configuring FC WAN COM ports, it is recommended to refer to the “Implementation and Planning Best Practices for EMC VPLEX Technical Notes” provided by Dell1.
In summary, the requirement for zoning FC WAN COM ports on a VPLEX Metro is to ensure that each WAN COM port in the local cluster is zoned to all WAN COM ports in the remote cluster, providing a robust and fault-tolerant communication network.
A RAID-C device has been built from a 100 GB extent and a 30 GB extent. How can this device be expanded?
Options:
RAID-C device cannot be expanded with unequal extent sizes
Add another RAID-C device to create a top-level device
Expand the 100 GB or 30 GB storage volume on the back-end array
Use concatenation by adding another extent to the device
Answer:
DExplanation:
To expand a RAID-C device that has been built from extents of unequal sizes, such as a 100 GB extent and a 30 GB extent, concatenation can be used. Concatenation allows for the addition of another extent to the existing RAID-C device, thereby increasing its overall size.
Understanding RAID-C: RAID-C is a type of RAID configuration used in VPLEX that allows for concatenation, which is the process of linking multiple storage extents to create a larger logical unit1.
Adding an Extent: To expand the RAID-C device, a new extent of the desired size can be added to the existing device. This new extent is concatenated to the end of the current extents, increasing the total capacity of the RAID-C device1.
VPLEX CLI Commands: The expansion is performed using VPLEX CLI commands. The specific command to add an extent to a RAID-C device would be similar to the storage-volume expand command, which instructs the system to include the new extent in the RAID-C device1.
Resizing Back-End Storage: If necessary, the back-end storage volumes (the physical storage on the array) that correspond to the extents may need to be resized to match the new configuration1.
Verification: After the expansion, it’s important to verify that the RAID-C device reflects the new size and that all extents are properly concatenated and functioning as expected1.
In summary, a RAID-C device built from extents of unequal sizes can be expanded by using concatenation to add another extent to the device. This method allows for flexibility in managing storage capacity within a VPLEX environment.

Which number in the exhibit highlights the Director-B front-end ports?
Options:
4
2
1
3
Answer:
BExplanation:
In a VPLEX system, each director module has front-end (FE) and back-end (BE) ports for connectivity. The FE ports are used to connect to hosts or out-of-fabric services such as management networks. Based on standard configurations and assuming that Director-A and Director-B are mirrored in layout, the number that highlights the Director-B front-end ports is typically 21.
Director Modules: VPLEX systems consist of director modules, each containing ports designated for specific functions. Director-B is one of these modules1.
Front-End Ports: The front-end ports on Director-B are used for host connectivity and are essential for the operation of the VPLEX system1.
Port Identification: During the installation and setup of a VPLEX system, correctly identifying and utilizing the FE ports is crucial. This includes connecting the VPLEX to the host environment and ensuring proper communication between the storage system and the hosts1.
Documentation Reference: For precise identification and configuration of the FE ports on Director-B, the Dell VPLEX Deploy Achievement documents provide detailed instructions and diagrams1.
Best Practices: It is recommended to follow the guidelines provided in the Dell VPLEX documentation for port identification and installation utilities to ensure correct setup and configuration of the VPLEX system1.
In summary, the number 2 in the exhibit corresponds to the Director-B front-end ports in a Dell VPLEX system, which are critical for host connectivity and system operation.
Once installed, how does VPLEX Cluster Witness communicate with each cluster to provide the health check heartbeats required for monitoring?
Options:
VPN Tunnel over IP to each management server
UDP over IP to each management server
Native iSCSI connections to each management server
In-band Fibre Channel to each management server
Answer:
AExplanation:
The VPLEX Cluster Witness communicates with each cluster using a VPN Tunnel over IP to the management servers. This method is used to provide the health check heartbeats required for monitoring the status of the clusters.
VPN Tunnel Creation: Initially, a VPN tunnel is established between the VPLEX Cluster Witness and each VPLEX cluster’s management server. This secure tunnel ensures that the communication for health checks is protected1.
Health Check Heartbeats: Through the VPN tunnel, the VPLEX Cluster Witness sends periodic health check heartbeats to each management server. These heartbeats are used to monitor the operational status of the clusters1.
Monitoring Cluster Health: The health check heartbeats are essential for the VPLEX Cluster Witness to determine the health of each cluster. If a heartbeat is missed, it may indicate a potential issue with the cluster1.
Failover Decisions: Based on the health check heartbeats, the VPLEX Cluster Witness can make informed decisions about failover actions if one of the clusters becomes unresponsive or encounters a failure1.
Configuration and Management: The configuration and management of the VPN tunnels and the health check mechanism are typically done through the VPLEX management console or CLI, following the best practices outlined in the Dell VPLEX Deploy Achievement documents1.
In summary, the VPLEX Cluster Witness uses a VPN Tunnel over IP to communicate with each cluster’s management server, providing the necessary health check heartbeats for continuous monitoring and ensuring high availability of the VPLEX system.
