Google Cloud Certified - Professional Cloud DevOps Engineer Exam Questions and Answers
You are currently planning how to display Cloud Monitoring metrics for your organization's Google Cloud projects. Your organization has three folders and six projects:
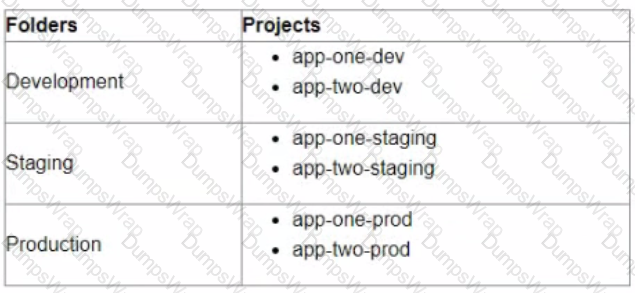
You want to configure Cloud Monitoring dashboards lo only display metrics from the projects within one folder You need to ensure that the dashboards do not display metrics from projects in the other folders You want to follow Google-recommended practices What should you do?
You are running an application on Compute Engine and collecting logs through Stackdriver. You discover that some personally identifiable information (PII) is leaking into certain log entry fields. You want to prevent these fields from being written in new log entries as quickly as possible. What should you do?
You are creating and assigning action items in a postmodern for an outage. The outage is over, but you need to address the root causes. You want to ensure that your team handles the action items quickly and efficiently. How should you assign owners and collaborators to action items?
You work for a global organization and run a service with an availability target of 99% with limited engineering resources. For the current calendar month you noticed that the service has 99 5% availability. You must ensure that your service meets the defined availability goals and can react to business changes including the upcoming launch of new features You also need to reduce technical debt while minimizing operational costs You want to follow Google-recommended practices What should you do?
Your company runs services by using Google Kubernetes Engine (GKE). The GKE clusters in the development environment run applications with verbose logging enabled. Developers view logs by using the kubect1 logs
command and do not use Cloud Logging. Applications do not have a uniform logging structure defined. You need to minimize the costs associated with application logging while still collecting GKE operational logs. What should you do?
You are performing a semi-annual capacity planning exercise for your flagship service You expect a service user growth rate of 10% month-over-month for the next six months Your service is fully containerized and runs on a Google Kubemetes Engine (GKE) standard cluster across three zones with cluster autoscaling enabled You currently consume about 30% of your total deployed CPU capacity and you require resilience against the failure of a zone. You want to ensure that your users experience minimal negative impact as a result of this growth o' as a result of zone failure while you avoid unnecessary costs How should you prepare to handle the predicted growth?
You are designing a system with three different environments: development, quality assurance (QA), and production.
Each environment will be deployed with Terraform and has a Google Kubemetes Engine (GKE) cluster created so that application teams can deploy their applications. Anthos Config Management will be used and templated to deploy
infrastructure level resources in each GKE cluster. All users (for example, infrastructure operators and application owners) will use GitOps. How should you structure your source control repositories for both Infrastructure as Code (laC) and application code?
Your company has a Google Cloud resource hierarchy with folders for production test and development Your cyber security team needs to review your company's Google Cloud security posture to accelerate security issue identification and resolution You need to centralize the logs generated by Google Cloud services from all projects only inside your production folder to allow for alerting and near-real time analysis. What should you do?
You support a web application that is hosted on Compute Engine. The application provides a booking service for thousands of users. Shortly after the release of a new feature, your monitoring dashboard shows that all users are experiencing latency at login. You want to mitigate the impact of the incident on the users of your service. What should you do first?
You are configuring the frontend tier of an application deployed in Google Cloud The frontend tier is hosted in ngmx and deployed using a managed instance group with an Envoy-based external HTTP(S) load balancer in front The application is deployed entirely within the europe-west2 region: and only serves users based in the United Kingdom. You need to choose the most cost-effective network tier and load balancing configuration What should you use?
You are developing reusable infrastructure as code modules. Each module contains integration tests that launch the module in a test project. You are using GitHub for source control. You need to Continuously test your feature branch and ensure that all code is tested before changes are accepted. You need to implement a solution to automate the integration tests. What should you do?
Your application services run in Google Kubernetes Engine (GKE). You want to make sure that only images from your centrally-managed Google Container Registry (GCR) image registry in the altostrat-images project can be deployed to the cluster while minimizing development time. What should you do?
You encountered a major service outage that affected all users of the service for multiple hours. After several hours of incident management, the service returned to normal, and user access was restored. You need to provide an incident summary to relevant stakeholders following the Site Reliability Engineering recommended practices. What should you do first?
Your company is developing applications that are deployed on Google Kubernetes Engine (GKE) Each team manages a different application You need to create the development and production environments for each team while you minimize costs Different teams should not be able to access other teams environments You want to follow Google-recommended practices What should you do?
You are part of an organization that follows SRE practices and principles. You are taking over the management of a new service from the Development Team, and you conduct a Production Readiness Review (PRR). After the PRR analysis phase, you determine that the service cannot currently meet its Service Level Objectives (SLOs). You want to ensure that the service can meet its SLOs in production. What should you do next?
You are developing the deployment and testing strategies for your CI/CD pipeline in Google Cloud You must be able to
• Reduce the complexity of release deployments and minimize the duration of deployment rollbacks
• Test real production traffic with a gradual increase in the number of affected users
You want to select a deployment and testing strategy that meets your requirements What should you do?
Your company is using HTTPS requests to trigger a public Cloud Run-hosted service accessible at the .a.run.app URL You need to give developers the ability to test the latest revisions of the service before the service is exposed to customers What should you do?
You support a high-traffic web application with a microservice architecture. The home page of the application displays multiple widgets containing content such as the current weather, stock prices, and news headlines. The main serving thread makes a call to a dedicated microservice for each widget and then lays out the homepage for the user. The microservices occasionally fail; when that happens, the serving thread serves the homepage with some missing content. Users of the application are unhappy if this degraded mode occurs too frequently, but they would rather have some content served instead of no content at all. You want to set a Service Level Objective (SLO) to ensure that the user experience does not degrade too much. What Service Level Indicator {SLI) should you use to measure this?
You have migrated an e-commerce application to Google Cloud Platform (GCP). You want to prepare the application for the upcoming busy season. What should you do first to prepare for the busy season?
Your team has recently deployed an NGINX-based application into Google Kubernetes Engine (GKE) and has exposed it to the public via an HTTP Google Cloud Load Balancer (GCLB) ingress. You want to scale the deployment of the application's frontend using an appropriate Service Level Indicator (SLI). What should you do?
You are leading a DevOps project for your organization. The DevOps team is responsible for managing the service infrastructure and being on-call for incidents. The Software Development team is responsible for writing, submitting, and reviewing code. Neither team has any published SLOs. You want to design a new joint-ownership model for a service between the DevOps team and the Software Development team. Which responsibilities should be assigned to each team in the new joint-ownership model?

You are writing a postmortem for an incident that severely affected users. You want to prevent similar incidents in the future. Which two of the following sections should you include in the postmortem? (Choose two.)
Your company runs an ecommerce website built with JVM-based applications and microservice architecture in Google Kubernetes Engine (GKE) The application load increases during the day and decreases during the night Your operations team has configured the application to run enough Pods to handle the evening peak load You want to automate scaling by only running enough Pods and nodes for the load What should you do?
Your company follows Site Reliability Engineering practices. You are the Incident Commander for a new. customer-impacting incident. You need to immediately assign two incident management roles to assist you in an effective incident response. What roles should you assign?
Choose 2 answers
You are ready to deploy a new feature of a web-based application to production. You want to use Google Kubernetes Engine (GKE) to perform a phased rollout to half of the web server pods.
What should you do?
You have an application running in Google Kubernetes Engine. The application invokes multiple services per request but responds too slowly. You need to identify which downstream service or services are causing the delay. What should you do?
You are performing a semiannual capacity planning exercise for your flagship service. You expect a service user growth rate of 10% month-over-month over the next six months. Your service is fully containerized and runs on Google Cloud Platform (GCP). using a Google Kubernetes Engine (GKE) Standard regional cluster on three zones with cluster autoscaler enabled. You currently consume about 30% of your total deployed CPU capacity, and you require resilience against the failure of a zone. You want to ensure that your users experience minimal negative impact as a result of this growth or as a result of zone failure, while avoiding unnecessary costs. How should you prepare to handle the predicted growth?
Your company follows Site Reliability Engineering practices. You are the person in charge of Communications for a large, ongoing incident affecting your customer-facing applications. There is still no estimated time for a resolution of the outage. You are receiving emails from internal stakeholders who want updates on the outage, as well as emails from customers who want to know what is happening. You want to efficiently provide updates to everyone affected by the outage. What should you do?
Your team is running microservices in Google Kubernetes Engine (GKE) You want to detect consumption of an error budget to protect customers and define release policies What should you do?
Your team of Infrastructure DevOps Engineers is growing, and you are starting to use Terraform to manage infrastructure. You need a way to implement code versioning and to share code with other team members. What should you do?
Your company is developing applications that are deployed on Google Kubernetes Engine (GKE). Each team manages a different application. You need to create the development and production environments for each team, while minimizing costs. Different teams should not be able to access other teams’ environments. What should you do?
You manage an application that is writing logs to Stackdriver Logging. You need to give some team members the ability to export logs. What should you do?
You support an application running on GCP and want to configure SMS notifications to your team for the most critical alerts in Stackdriver Monitoring. You have already identified the alerting policies you want to configure this for. What should you do?
You are building an application that runs on Cloud Run The application needs to access a third-party API by using an API key You need to determine a secure way to store and use the API key in your application by following Google-recommended practices What should you do?
You work for a global organization and are running a monolithic application on Compute Engine You need to select the machine type for the application to use that optimizes CPU utilization by using the fewest number of steps You want to use historical system metncs to identify the machine type for the application to use You want to follow Google-recommended practices What should you do?
You are building and running client applications in Cloud Run and Cloud Functions Your client requires that all logs must be available for one year so that the client can import the logs into their logging service You must minimize required code changes What should you do?
You recently migrated an ecommerce application to Google Cloud. You now need to prepare the application for the upcoming peak traffic season. You want to follow Google-recommended practices. What should you do first to prepare for the busy season?
You are configuring your CI/CD pipeline natively on Google Cloud. You want builds in a pre-production Google Kubernetes Engine (GKE) environment to be automatically load-tested before being promoted to the production GKE environment. You need to ensure that only builds that have passed this test are deployed to production. You want to follow Google-recommended practices. How should you configure this pipeline with Binary Authorization?
You manage several production systems that run on Compute Engine in the same Google Cloud Platform (GCP) project. Each system has its own set of dedicated Compute Engine instances. You want to know how must it costs to run each of the systems. What should you do?
You have deployed a fleet Of Compute Engine instances in Google Cloud. You need to ensure that monitoring metrics and logs for the instances are visible in Cloud Logging and Cloud Monitoring by your company's operations and cyber
security teams. You need to grant the required roles for the Compute Engine service account by using Identity and Access Management (IAM) while following the principle of least privilege. What should you do?
Your company runs applications in Google Kubernetes Engine (GKE) that are deployed following a GitOps methodology.
Application developers frequently create cloud resources to support their applications. You want to give developers the ability to manage infrastructure as code, while ensuring that you follow Google-recommended practices. You need to ensure that infrastructure as code reconciles periodically to avoid configuration drift. What should you do?
You use Spinnaker to deploy your application and have created a canary deployment stage in the pipeline. Your application has an in-memory cache that loads objects at start time. You want to automate the comparison of the canary version against the production version. How should you configure the canary analysis?
You have a CI/CD pipeline that uses Cloud Build to build new Docker images and push them to Docker Hub. You use Git for code versioning. After making a change in the Cloud Build YAML configuration, you notice that no new artifacts are being built by the pipeline. You need to resolve the issue following Site Reliability Engineering practices. What should you do?
Some of your production services are running in Google Kubernetes Engine (GKE) in the eu-west-1 region. Your build system runs in the us-west-1 region. You want to push the container images from your build system to a scalable registry to maximize the bandwidth for transferring the images to the cluster. What should you do?
Your organization uses a change advisory board (CAB) to approve all changes to an existing service You want to revise this process to eliminate any negative impact on the software delivery performance What should you do?
Choose 2 answers
You want to share a Cloud Monitoring custom dashboard with a partner team What should you do?
You support a high-traffic web application that runs on Google Cloud Platform (GCP). You need to measure application reliability from a user perspective without making any engineering changes to it. What should you do?
Choose 2 answers
