Microsoft Azure AI Fundamentals Questions and Answers
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:

Explanation:
Features
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Explore fundamental principles of machine learning,” data values that influence the prediction of a model are called features. In the context of machine learning, a feature is an individual measurable property, attribute, or input variable used by the model to make predictions.
Features are the independent variables that describe the characteristics of the data. For example, in a housing price prediction model, features might include square footage, location, number of bedrooms, and year built. These inputs help the model understand relationships in the data so it can predict the target outcome (the house price).
Microsoft Learn explains that features are the input variables that the algorithm uses to identify patterns and relationships in the training data. During training, the model learns how changes in these features influence the label (also known as the dependent variable or target variable). The label is the value the model tries to predict—such as “price,” “category,” or “yes/no.”
Here’s how the other options differ:
Dependent variables (labels): These are the outcomes or target values the model predicts, not the inputs.
Identifiers: These are unique keys (like customer ID or transaction ID) used to distinguish records but not to influence predictions.
Labels: As mentioned, labels are the results the model tries to predict.
Therefore, based on the AI-900 learning objectives and Microsoft’s official explanation, the data values that influence the prediction of a model—that is, the input variables that guide the model’s learning—are called features. These features form the foundation of the model’s predictive capabilities and directly impact its accuracy and performance.
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:

Explanation:
Classification
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe features of common AI workloads”, classification is a supervised machine learning technique used when the goal is to predict which category or class an item belongs to. In supervised learning, the model is trained with labeled data—data that already contains known outcomes. The system learns patterns and relationships between input features and their corresponding labels so it can predict future classifications accurately.
In the scenario provided — “A banking system that predicts whether a loan will be repaid” — the model’s output is a binary decision, meaning there are two possible outcomes:
The loan will be repaid (positive class)
The loan will not be repaid (negative class)
This kind of problem involves predicting a discrete value (a label or category), not a continuous numeric output. Therefore, it perfectly fits the classification type of machine learning.
The AI-900 learning materials describe classification as being used in many real-world examples, including:
Determining whether an email is spam or not spam.
Predicting whether a customer will churn (leave) or stay.
Detecting fraudulent transactions.
Assessing medical test results as positive or negative.
By contrast:
Regression predicts continuous numeric values, such as predicting house prices, temperatures, or sales revenue. It would not apply here because repayment prediction is not a numeric value but a categorical decision.
Clustering is an unsupervised learning method that groups similar data points without predefined categories, such as segmenting customers by purchasing behavior.
Thus, based on Microsoft’s Responsible AI and AI-900 study guide concepts, a banking system that predicts whether a loan will be repaid uses the Classification type of machine learning.
You have insurance claim reports that are stored as text.
You need to extract key terms from the reports to generate summaries.
Which type of Al workload should you use?
Options:
conversational Al
anomaly detection
natural language processing
computer vision
Answer:
CExplanation:
According to the AI-900 study guide and Microsoft Learn module “Identify features of natural language processing workloads”, Natural Language Processing (NLP) enables computers to understand, interpret, and generate human language. Tasks such as extracting key terms, summarizing documents, identifying topics, or determining sentiment fall under NLP workloads.
In this question, you have insurance claim reports stored as text, and you need to extract key terms to generate summaries. This matches the Text Analytics service in Azure Cognitive Services, which uses NLP techniques such as key phrase extraction to identify important concepts within textual data.
The other options are incorrect because:
A. Conversational AI focuses on chatbots or dialogue systems.
B. Anomaly detection identifies unusual data patterns, not textual meaning.
D. Computer vision processes image or video content, not text.
Therefore, extracting key terms from documents is a clear example of Natural Language Processing.
What should you use to identify similar faces in a set of images?
Options:
Azure Al Vision
Azure Al Custom Vision
Azure Al Language
Azure OpenAI Service
Answer:
AExplanation:
The correct service to identify similar faces in a set of images is Azure AI Vision, which includes the Face API capability. According to the Microsoft Learn module “Analyze images with Azure AI Vision”, this service provides prebuilt models for face detection, facial recognition, and similarity matching.
The Face API can detect individual faces in images and extract unique facial features to create a face embedding (a numerical representation of the face). It then compares these embeddings across multiple images to determine whether faces are similar or belong to the same person. This functionality is commonly used in identity verification, photo management systems, and security solutions.
The other options are incorrect:
B. Azure AI Custom Vision is used for custom image classification or object detection but does not provide face similarity or recognition features.
C. Azure AI Language processes text-based data (sentiment, entities, key phrases) — not visual content.
D. Azure OpenAI Service focuses on text generation, summarization, and conversation, not facial analysis.
Therefore, the Microsoft-verified service for identifying similar faces across images is A. Azure AI Vision.
You plan to apply Text Analytics API features to a technical support ticketing system.
Match the Text Analytics API features to the appropriate natural language processing scenarios.
To answer, drag the appropriate feature from the column on the left to its scenario on the right. Each feature may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

Box1: Sentiment analysis
Sentiment Analysis is the process of determining whether a piece of writing is positive, negative or neutral.
Box 2: Broad entity extraction
Broad entity extraction: Identify important concepts in text, including key
Key phrase extraction/ Broad entity extraction: Identify important concepts in text, including key phrases and named entities such as people, places, and organizations.
Box 3: Entity Recognition
Named Entity Recognition: Identify and categorize entities in your text as people, places, organizations, date/time, quantities, percentages, currencies, and more. Well-known entities are also recognized and linked to more information on the web.
You are developing a conversational AI solution that will communicate with users through multiple channels including email, Microsoft Teams, and webchat.
Which service should you use?
Options:
Text Analytics
Azure Bot Service
Translator
Form Recognizer
Answer:
BExplanation:
According to the Microsoft Azure AI Fundamentals official study guide and Microsoft Learn module “Describe features of conversational AI workloads on Azure”, Azure Bot Service is the core Azure platform for building, testing, deploying, and managing conversational agents or chatbots. These bots can communicate with users across multiple channels, including email, Microsoft Teams, Slack, Facebook Messenger, and webchat.
Azure Bot Service integrates deeply with the Bot Framework SDK and Azure Cognitive Services such as Language Understanding (LUIS) or Azure AI Language, enabling natural language processing and multi-channel message delivery. The service abstracts away channel management, meaning that developers can build one bot logic that connects seamlessly to several communication platforms.
Option analysis:
A. Text Analytics is a Cognitive Service used for text mining tasks like key phrase extraction, language detection, and sentiment analysis — not for building chatbots.
C. Translator provides language translation but cannot manage conversations or multi-channel delivery.
D. Form Recognizer extracts structured information from documents and forms — unrelated to conversational interaction.
The AI-900 course explicitly defines Azure Bot Service as “a managed platform that enables intelligent, multi-channel conversational experiences between users and bots.” This service allows businesses to unify chat experiences across multiple digital communication channels.
Thus, based on the official Microsoft Learn content and AI-900 syllabus, the best and verified answer is B. Azure Bot Service, as it is the designated Azure solution for deploying a single conversational AI experience accessible from multiple platforms such as email, Teams, and webchat.
For each of the following statements. select Yes if the statement is true. Otherwise, select No. NOTE; Each correct selection is worth one point

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of Computer Vision workloads on Azure”, the Custom Vision service is a part of Azure Cognitive Services that allows users to build, train, and deploy custom image classification and object detection models. It is primarily designed for still-image analysis, not video processing.
“The Custom Vision service can be used to detect objects in an image.” – Yes.This is correct. The Custom Vision service supports two major model types: classification (categorizing entire images) and object detection (identifying and locating multiple objects within a single image). In object detection mode, the model outputs both the object’s category and its position in the image using bounding boxes. This capability is emphasized in the AI-900 curriculum as an example of applying computer vision to real-world scenarios, such as identifying products on shelves or detecting equipment parts in manufacturing.
“The Custom Vision service requires that you provide your own data to train the model.” – Yes.This statement is also true. Unlike prebuilt computer vision models, Custom Vision is a trainable model that requires users to upload their own labeled images to create a domain-specific AI model. The model’s accuracy depends on the quality and quantity of this user-provided data. The AI-900 study materials explain that Custom Vision is used when prebuilt models do not meet specific needs, enabling businesses to train models tailored to unique image sets.
“The Custom Vision service can be used to analyze video files.” – No.This is incorrect. Custom Vision is limited to image-based analysis. To analyze video content (detecting objects or motion in moving frames), Azure provides Video Indexer, which is a separate service designed for extracting insights from video files, including speech, objects, faces, and emotions.
In which two scenarios can you use a speech synthesis solution? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Options:
an automated voice that reads back a credit card number entered into a telephone by using a numeric keypad
generating live captions for a news broadcast
extracting key phrases from the audio recording of a meeting
an Al character in a computer game that speaks audibly to a player
Answer:
A, DExplanation:
According to the Microsoft Learn module “Explore speech capabilities of Azure AI” and the AI-900 Official Study Guide, speech synthesis (also known as text-to-speech) is the process of converting written text into spoken audio output. Azure’s Speech service provides this functionality, allowing applications to produce human-like voices dynamically.
Let’s evaluate each scenario:
A. Automated voice that reads back a credit card number entered into a telephone keypad → YesThis is a classic text-to-speech (TTS) use case. The application converts numeric or textual input (such as a credit card number) into audio output that the caller hears. Azure Speech service can handle such voice responses in automated phone systems or IVR (Interactive Voice Response) setups.
B. Generating live captions for a news broadcast → NoThis is a speech-to-text scenario (speech recognition), not speech synthesis. It involves converting audio speech into written text.
C. Extracting key phrases from an audio recording of a meeting → NoThis involves speech-to-text followed by text analytics, not speech synthesis.
D. An AI character in a computer game that speaks audibly to a player → YesThis is a direct example of speech synthesis, where the character’s dialog text is converted into realistic spoken output for immersive interaction.
Therefore, based on Microsoft’s AI-900 curriculum, speech synthesis is used in applications that convert text into audible speech, such as automated voice systems or interactive digital characters.
You need to build an app that will identify celebrities in images.
Which service should you use?
Options:
Azure OpenAI Service
Azure Machine Learning
conversational language understanding (CLU)
Azure Al Vision
Answer:
DExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official learning path, the appropriate service for recognizing celebrities in images is Azure AI Vision (formerly Computer Vision). This service is part of Azure’s Cognitive Services suite and specializes in analyzing visual content using pretrained deep learning models. One of its built-in capabilities, as documented in Microsoft Learn: “Analyze images with Azure AI Vision”, includes object detection, face detection, and celebrity recognition.
The Azure AI Vision Analyze API can detect and identify thousands of objects, brands, and celebrities. When an image is submitted to the service, the model compares detected faces to a known database of public figures and returns metadata including celebrity names, confidence scores, and bounding box coordinates. This makes it ideal for applications that need to recognize well-known individuals automatically—such as media cataloging, content tagging, or entertainment apps.
The other options are incorrect:
A. Azure OpenAI Service provides generative AI and language models (like GPT-4), but it cannot analyze image content directly in the context of AI-900 fundamentals.
B. Azure Machine Learning is for custom model training and deployment, not a prebuilt vision recognition service.
C. Conversational Language Understanding (CLU) processes natural language input, not images.
Therefore, the correct service for identifying celebrities in images is D. Azure AI Vision.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

The Translator service, part of Microsoft Azure Cognitive Services, is designed specifically for text translation between multiple languages. It is a cloud-based neural machine translation service that supports more than 100 languages. According to Microsoft Learn’s module “Translate text with the Translator service”, this service provides two main capabilities: text translation and automatic language detection.
“You can use the Translator service to translate text between languages.” → YesThis statement is true. The primary purpose of the Translator service is to translate text accurately and efficiently between supported languages, such as English to Spanish or French to Japanese. It maintains contextual meaning using neural machine translation models.
“You can use the Translator service to detect the language of a given text.” → YesThis statement is also true. The Translator service includes automatic language detection, which determines the source language before translation. For instance, if a user submits text in an unknown language, the service can identify it automatically before performing translation.
“You can use the Translator service to transcribe audible speech into text.” → NoThis statement is false. Transcribing speech (audio) into text is a function of the Azure Speech service, specifically the Speech-to-Text API, not the Translator service.
Therefore, the Translator service is used for text translation and language detection, while speech transcription belongs to the Speech service.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

In Azure Machine Learning Designer, the Dataset output visualization feature is specifically used to explore and understand the distribution of values in potential feature columns before model training begins. This capability is critical for data exploration and preprocessing, two essential stages of the machine learning pipeline described in the Microsoft Azure AI Fundamentals (AI-900) and Azure Machine Learning learning paths.
When a dataset is imported into Azure Machine Learning Designer, users can right-click on the dataset output port and select “Visualize”. This launches the dataset visualization pane, which provides detailed statistical summaries for each column, including:
Data type (numeric, categorical, string, Boolean)
Minimum, maximum, mean, and standard deviation values for numeric columns
Frequency counts and distinct values for categorical columns
Missing value counts
This visual inspection helps determine which columns should be used as features, which might need normalization or encoding, and which contain missing or irrelevant data. It is a vital step in ensuring the dataset is clean and ready for model training.
Let’s examine why other options are incorrect:
Normalize Data module is used to scale numeric data, not to visualize distributions.
Select Columns in Dataset module is used to include or exclude columns, not to analyze them.
Evaluation results visualization feature is used after model training to interpret performance metrics like accuracy or recall, not data distributions.
Therefore, based on official Microsoft documentation and AI-900 study materials, to explore the distribution of values in potential feature columns, you use the Dataset output visualization feature in Azure Machine Learning Designer.
You need to generate cartoons for use in a brochure. Each cartoon will be based on a text description.
Which Azure OpenAI model should you use?
Options:
Codex
DALL-E
GPT-3.5
GPT-4
Answer:
BExplanation:
To generate cartoons or images from text descriptions, the correct Azure OpenAI model is DALL-E. As described in Microsoft’s OpenAI integration documentation, DALL-E is a generative image model that converts natural language prompts into images, illustrations, and artwork.
Codex is for code generation, GPT-3.5 and GPT-4 are for text and reasoning tasks, not image creation. Therefore, B. DALL-E is correct.
You have a webchat bot that provides responses from a QnA Maker knowledge base.
You need to ensure that the bot uses user feedback to improve the relevance of the responses over time.
What should you use?
Options:
key phrase extraction
sentiment analysis
business logic
active learning
Answer:
DExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) study guide and the official Microsoft Learn module “Describe features of common AI workloads”, QnA Maker (now part of Azure AI Language services) allows developers to build, train, and publish a knowledge base that provides natural-language answers to user queries. A key capability of this service is active learning, which enables the knowledge base to automatically suggest improvements by analyzing user feedback and usage patterns.
Active learning is an iterative process in which the service observes real user interactions and identifies ambiguous questions or pairs of similar questions that produce uncertain or multiple answers. The system then recommends updates or refinements to the knowledge base to improve the accuracy and relevance of responses. This feedback loop helps ensure that over time, the chatbot’s responses align more closely with actual user expectations and language variations.
In contrast:
A. Key phrase extraction identifies main ideas in text and is used in content summarization, not in response optimization.
B. Sentiment analysis detects emotional tone (positive, negative, neutral), but it doesn’t refine QnA responses.
C. Business logic defines operational rules in an application, not machine learning-driven feedback.
The AI-900 guide specifically emphasizes that QnA Maker supports active learning to improve the quality of answers based on end-user feedback, making this the verified and official Microsoft answer.
Reference (from Microsoft Learn AI-900 content):
“Active learning uses feedback from end users to automatically suggest improvements to a knowledge base, helping improve the accuracy of answers over time.”
You are building a tool that will process images from retail stores and identity the products of competitors.
The solution must be trained on images provided by your company.
Which Azure Al service should you use?
Options:
Azure Al Custom Vision
Azure Al Computer Vision
Face
Azure Al Document Intelligence
Answer:
AExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and Microsoft Learn documentation, Azure AI Custom Vision is specifically designed for training custom image classification and object detection models using images that a company provides. In this scenario, the company wants to identify competitor products from images captured in retail stores — a classic use case for custom image classification or object detection, depending on whether you are labeling entire images or identifying multiple items within an image.
Azure AI Custom Vision allows users to:
Upload their own labeled training images.
Train a model that learns to recognize specific objects (in this case, competitor products).
Evaluate, iterate, and deploy the model as an API endpoint for real-time inference.
This fits perfectly with the requirement that the solution “must be trained on images provided by your company.” The key phrase here indicates the need for a custom-trained model rather than a prebuilt one.
The other options are not suitable for this scenario:
B. Azure AI Computer Vision provides prebuilt models for general-purpose image understanding (e.g., detecting common objects, reading text, describing scenes). It is not intended for training on custom datasets.
C. Face service is limited to detecting and recognizing human faces; it cannot be trained to identify products.
D. Azure AI Document Intelligence (formerly Form Recognizer) is focused on extracting structured data from documents and forms, not analyzing retail images.
Therefore, per Microsoft’s official AI-900 training content, when a solution must be trained on custom company images to recognize specific products, the appropriate service is Azure AI Custom Vision.
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:
Explanation:

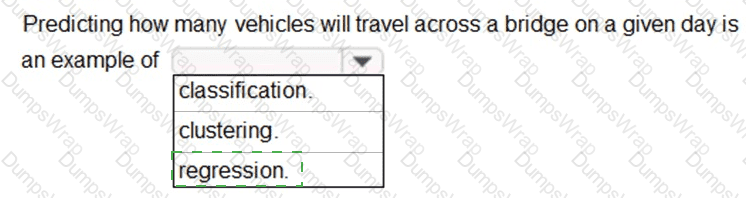
In the context of Microsoft Azure AI Fundamentals (AI-900) and general machine learning principles, regression refers to a type of supervised learning used to predict continuous numerical values based on historical data. The goal of regression is to model the relationship between input variables (features) and a continuous output variable (target).
In this scenario, the task is to predict how many vehicles will travel across a bridge on a given day. The number of vehicles is a numerical value that can vary continuously depending on factors such as time of day, weather, weekday/weekend, or traffic trends. Because the output is numeric and not categorical, this problem type clearly fits into regression analysis.
Microsoft’s official learning content for AI-900, under “Identify features of regression and classification machine learning models,” specifies that regression models are used to predict values such as sales forecasts, demand estimation, temperature prediction, or traffic volume—all of which share the same underlying objective: predicting a quantity.
To clarify other options:
Classification is used when predicting categories or discrete classes, such as determining whether an email is spam or not spam, or if an image contains a cat or a dog.
Clustering is an unsupervised learning technique used to group similar data points without predefined labels (for example, grouping customers by purchasing behavior).
Since predicting the number of vehicles results in a continuous numerical output, it aligns precisely with the regression workload type described in the Microsoft AI-900 study materials.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

Box 1: No
Box 2: Yes
Box 3: Yes
Anomaly detection encompasses many important tasks in machine learning:
Identifying transactions that are potentially fraudulent.
Learning patterns that indicate that a network intrusion has occurred.
Finding abnormal clusters of patients.
Checking values entered into a system.
Select the answer that correctly completes the sentence.
Options:
Answer:
Explanation:

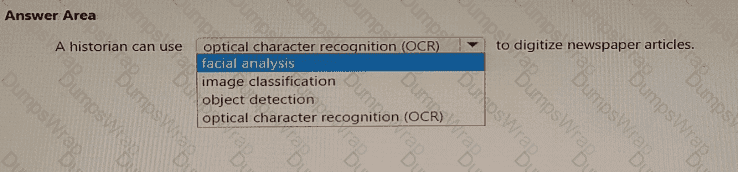
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure,” Optical Character Recognition (OCR) is a computer vision capability that detects and extracts printed or handwritten text from images or scanned documents and converts it into machine-readable digital text.
In this scenario, a historian wants to digitize newspaper articles — which means converting physical or scanned images of printed text into digital text for easier searching, archiving, and analysis. This is exactly the function of OCR. By using OCR, the historian can take photos or scans of old newspapers and extract the words into editable digital documents, preserving valuable historical information.
OCR is a key feature of the Azure Computer Vision service, which provides capabilities such as:
Extracting text from images or PDFs.
Reading both printed and handwritten text in multiple languages.
Converting physical documents into searchable digital files.
Let’s examine the incorrect options:
Facial analysis: Detects facial features, age, gender, and emotions — unrelated to text extraction.
Image classification: Identifies what an image contains (e.g., “dog,” “car,” or “building”) but doesn’t extract text.
Object detection: Identifies and locates objects within an image using bounding boxes, not suitable for text recognition.
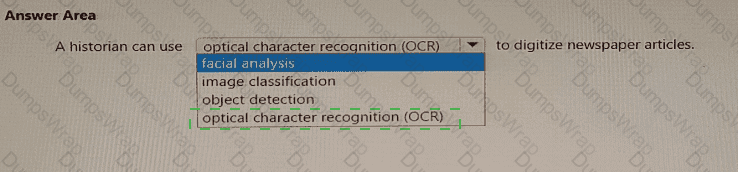
Therefore, to digitize newspaper articles and convert printed words into editable digital text, the correct technology to use is Optical Character Recognition (OCR), provided by the Azure Computer Vision API.
✅ Final Answer: optical character recognition (OCR)
You have an Internet of Things (loT) device that monitors engine temperature.
The device generates an alert if the engine temperature deviates from expected norms.
Which type of Al workload does the device represent?
Options:
natural language processing (NLP)
computer vision
anomaly detection
knowledge mining
Answer:
CExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore fundamental principles of machine learning,” anomaly detection is a machine learning workload used to identify data points or patterns that deviate significantly from expected behavior.
In this scenario, the IoT device monitors engine temperature and generates alerts when the readings deviate from normal operating ranges. This directly matches the definition of anomaly detection, where the AI system learns what “normal” looks like and identifies outliers or abnormal conditions that may indicate potential issues.
Common real-world uses of anomaly detection include:
Detecting equipment malfunctions or overheating in IoT systems.
Identifying fraudulent transactions in finance.
Detecting unusual spikes or drops in system metrics (e.g., temperature, traffic, or pressure).
Other options are incorrect:
A. NLP (Natural Language Processing): Focuses on understanding and interpreting human language, not sensor data.
B. Computer Vision: Involves analyzing images or videos, which is unrelated to temperature data.
D. Knowledge Mining: Refers to extracting information from large document stores, not identifying abnormal readings.
Select the answer that correctly completes the sentence.
Options:
Answer:
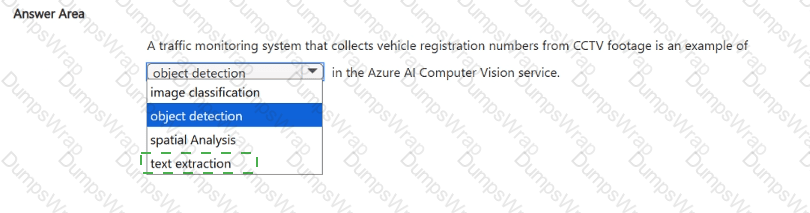
Explanation:
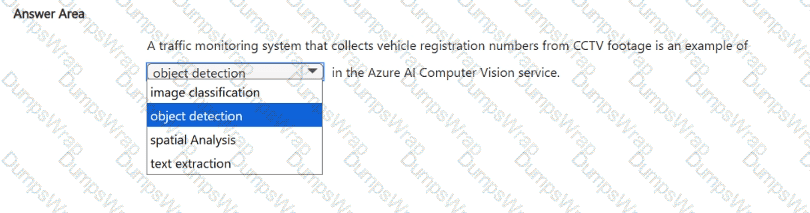
Text extraction.
According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn documentation for Azure AI Vision (formerly Computer Vision), text extraction—also known as Optical Character Recognition (OCR)—is the computer vision capability that detects and extracts printed or handwritten text from images and video frames.
In this scenario, a traffic monitoring system collects vehicle registration numbers (license plates) from CCTV footage. These registration numbers are alphanumeric text that must be read and converted into digital form for processing, storage, or analysis. The Azure AI Vision service’s OCR (text extraction) feature performs this function. It analyzes each frame from the video feed, detects text regions (the license plates), and converts the visual text into machine-readable text data.
This process is widely used in Automatic Number Plate Recognition (ANPR) systems that support law enforcement, toll booths, and parking management solutions. The OCR model can handle variations in font, lighting, and angle to accurately extract license plate numbers.
The other options describe different vision capabilities:
Image classification assigns an image to a general category (e.g., “car,” “truck,” or “bike”), not text extraction.
Object detection identifies and locates objects in images using bounding boxes (e.g., detecting the car itself), but not the text written on the car.
Spatial analysis tracks people or objects in a defined physical space (e.g., counting individuals entering a building), not reading text.
Therefore, for a traffic monitoring system that identifies vehicle registration numbers from CCTV footage, the most accurate Azure AI Vision capability is Text extraction (OCR).
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of the Computer Vision and Custom Vision services”, the Custom Vision service is used to train, deploy, and improve custom image classification and object detection models using your own labeled data.
Multilabel or Multiclass Selection – NOThe statement is false because the Multilabel or Multiclass choice applies only to image classification models, not object detection models. In image classification, “Multiclass” means one label per image, while “Multilabel” means multiple labels per image. In contrast, object detection models identify and locate multiple objects in an image using bounding boxes; thus, this classification-type selection does not apply.
Object Detection Locates Content in an Image – YESThis statement is true. The object detection functionality in Custom Vision is designed to both identify what objects appear in an image and determine their location through bounding box coordinates. For example, a model could detect and locate multiple products on a store shelf. Microsoft documentation describes object detection as “identifying the presence and location of objects in an image.”
Predefined Domains – YESThis statement is true as well. When you create a new Custom Vision project, you must select a domain, which is a predefined optimization setting tailored to specific use cases such as retail, food, landmarks, or general images. These domains are designed to improve model accuracy by applying specialized transfer learning features based on the type of images you will analyze.
In summary:
Classification type (Multilabel/Multiclass): No (only for classification models)
Detect object location: Yes
Choose predefined domain: Yes
Capturing text from images is an example of which type of Al capability?
Options:
text analysis
optical character recognition (OCR)
image description
object detection
Answer:
BExplanation:
The correct answer is B. Optical character recognition (OCR).
OCR is a key capability within the Computer Vision and Document Intelligence services in Azure AI that enables systems to detect and extract printed or handwritten text from images and scanned documents.
When capturing text from images, OCR technology analyzes visual patterns (shapes of letters and numbers) and converts them into machine-readable text. For example, a photo of a receipt, street sign, or printed report can be processed to extract textual content programmatically.
A (Text analysis): Applies to NLP tasks such as sentiment detection or key phrase extraction, not image processing.
C (Image description): Generates captions describing the scene or objects in an image.
D (Object detection): Identifies and locates objects but does not extract text.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

This question is drawn from the Microsoft Azure AI Fundamentals (AI-900) syllabus section “Describe features of natural language processing (NLP) workloads on Azure.” According to the Microsoft Learn materials, Natural Language Processing (NLP) is a branch of artificial intelligence that allows computers to analyze, understand, and generate human language. NLP enables machines to work with text or speech data in a way that extracts meaning, sentiment, and intent.
Microsoft defines NLP as enabling scenarios such as language detection, text classification, key phrase extraction, sentiment analysis, and named entity recognition. The example given—classifying emails as “work-related” or “personal”—is a text classification task, which falls under NLP capabilities. The AI model processes the textual content of emails, identifies linguistic patterns, and categorizes them based on the detected topic or context.
Let’s analyze the other options:
Predict the number of future car rentals → This is a forecasting task, handled by machine learning regression models, not NLP.
Predict which website visitors will make a transaction → This is a classification or prediction problem in machine learning, not NLP, since it deals with behavioral or numerical data rather than language.
Stop a process in a factory when extremely high temperatures are registered → This is an IoT or anomaly detection scenario, focusing on sensor data, not language understanding.
Therefore, only classifying email messages as work-related or personal correctly represents an NLP use case. It illustrates how NLP can analyze written text and make intelligent categorizations—a key capability covered in AI-900’s natural language workloads section.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:
Statement
Yes / No
Providing an explanation of the outcome of a credit loan application is an example of the Microsoft transparency principle for responsible AI.
Yes
A triage bot that prioritizes insurance claims based on injuries is an example of the Microsoft reliability and safety principle for responsible AI.
Yes
An AI solution that is offered at different prices for different sales territories is an example of the Microsoft inclusiveness principle for responsible AI.
No
This question is based on the Responsible AI principles defined by Microsoft, which are part of the AI-900 Microsoft Azure AI Fundamentals curriculum. Microsoft’s Responsible AI framework consists of six key principles: Fairness, Reliability and Safety, Privacy and Security, Inclusiveness, Transparency, and Accountability. Each principle ensures that AI systems are developed and used in a way that benefits people and society responsibly.
Transparency Principle – YesProviding an explanation for a loan decision aligns with the Transparency principle. Microsoft defines transparency as helping users and stakeholders understand how AI systems make decisions. For example, when a credit scoring AI model approves or denies a loan, explaining the factors that influenced that outcome (such as credit history or income level) ensures that customers understand the reasoning process. This builds trust and supports responsible deployment.
Reliability and Safety Principle – YesA triage bot that prioritizes insurance claims based on injury severity relates directly to Reliability and Safety. This principle ensures AI systems operate consistently, perform accurately, and produce dependable outcomes. In the case of the triage bot, it must reliably assess the input data (injury descriptions) and rank claims appropriately to avoid harm or misjudgment, aligning with Microsoft’s emphasis on designing AI systems that are safe and robust.
Inclusiveness Principle – NoAn AI solution priced differently across sales territories is not related to Inclusiveness. Inclusiveness focuses on ensuring accessibility and eliminating bias or exclusion for all users—especially those with disabilities or underrepresented groups. Pricing strategy is a business decision, not an inclusiveness issue. Therefore, this statement is No.
In summary, based on the AI-900 Responsible AI principles, the correct selections are:
You use Azure Machine Learning designer to publish an inference pipeline.
Which two parameters should you use to consume the pipeline? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Options:
the model name
the training endpoint
the authentication key
the REST endpoint
Answer:
C, DExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore Azure Machine Learning”, when you publish an inference pipeline (a deployed web service for real-time predictions) using Azure Machine Learning designer, you make the model accessible as a RESTful endpoint. Consumers—such as applications, scripts, or services—interact with this endpoint to submit data and receive predictions.
To securely access this deployed pipeline, two critical parameters are required:
REST endpoint (Option D):The REST endpoint is a URL automatically generated when the inference pipeline is deployed. It defines the network location where clients send HTTP POST requests containing input data (usually in JSON format). The endpoint routes these requests to the deployed model, which processes the data and returns prediction results. The REST endpoint acts as the primary access point for consuming the model’s inferencing capability programmatically.
Authentication key (Option C):The authentication key (or API key) is a security token provided by Azure to ensure that only authorized users or systems can access the endpoint. When invoking the REST service, the key must be included in the request header (typically as the value of the Authorization header). This mechanism enforces secure, authenticated access to the deployed model.
The other options are incorrect:
A. The model name is not required to consume the endpoint; it is used internally within the workspace.
B. The training endpoint is used for training pipelines, not for inference.
Therefore, according to Microsoft’s official AI-900 learning objectives and Azure Machine Learning documentation, when consuming a published inference pipeline, you must use both the REST endpoint (D) and the authentication key (C). These parameters ensure secure, controlled, and programmatic access to the deployed AI model for real-time predictions.
You need to scan the news for articles about your customers and alert employees when there is a negative article. Positive articles must be added to a press book.
Which natural language processing tasks should you use to complete the process? To answer, drag the appropriate tasks to the correct locations. Each task may be used once, more than once, or not at all. You may need to drag the split bar between panes or scroll to view content.
NOTE: Each correct selection is worth one point.
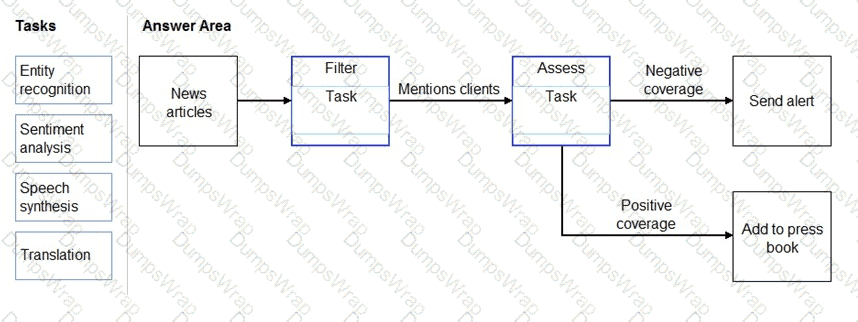
Options:
Answer:
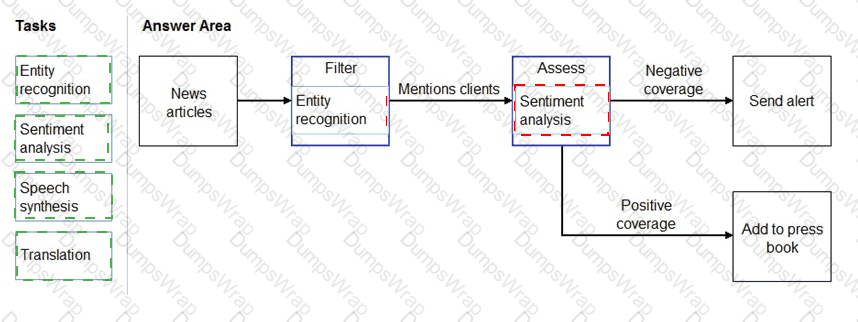
Explanation:
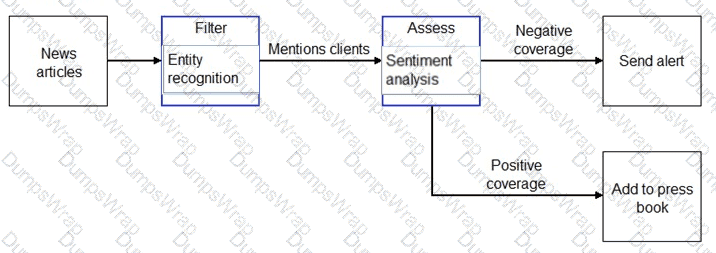
Box 1: Entity recognition
the Named Entity Recognition module in Machine Learning Studio (classic), to identify the names of things, such as people, companies, or locations in a column of text.
Named entity recognition is an important area of research in machine learning and natural language processing (NLP), because it can be used to answer many real-world questions, such as:
Which companies were mentioned in a news article?
Does a tweet contain the name of a person? Does the tweet also provide his current location?
Were specified products mentioned in complaints or reviews?
Box 2: Sentiment Analysis
The Text Analytics API ' s Sentiment Analysis feature provides two ways for detecting positive and negative sentiment. If you send a Sentiment Analysis request, the API will return sentiment labels (such as " negative " , " neutral " and " positive " ) and confidence scores at the sentence and document-level.
You have a frequently asked questions (FAQ) PDF file.
You need to create a conversational support system based on the FAQ.
Which service should you use?
Options:
QnA Maker
Text Analytics
Computer Vision
Language Understanding (LUIS)
Answer:
AExplanation:
A FAQ PDF file contains structured Q & A content. The QnA Maker (now part of Azure Language Service) can automatically extract questions and answers from such a document and build a knowledge base for conversational bots. This allows users to interact naturally with the content via chat interfaces.
Other options:
B. Text Analytics → Extracts insights, not conversational content.
C. Computer Vision → Used for image analysis.
D. LUIS → Handles intent detection, not static question–answer responses.
Match the types of AI workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
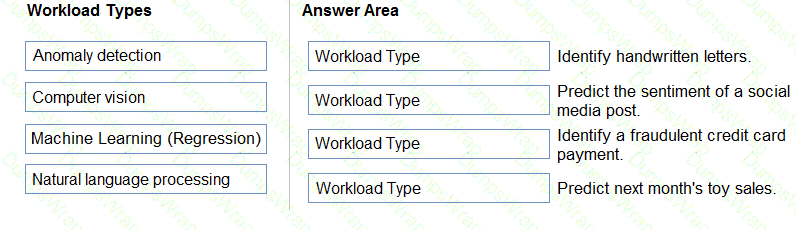
Options:
Answer:
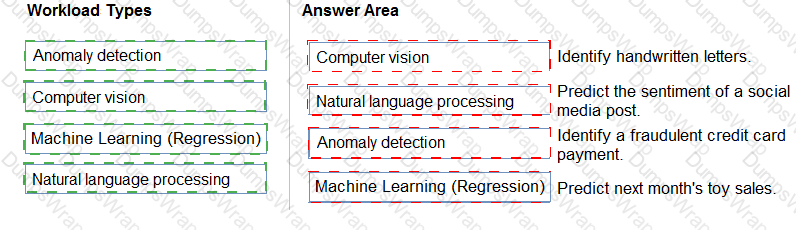
Explanation:
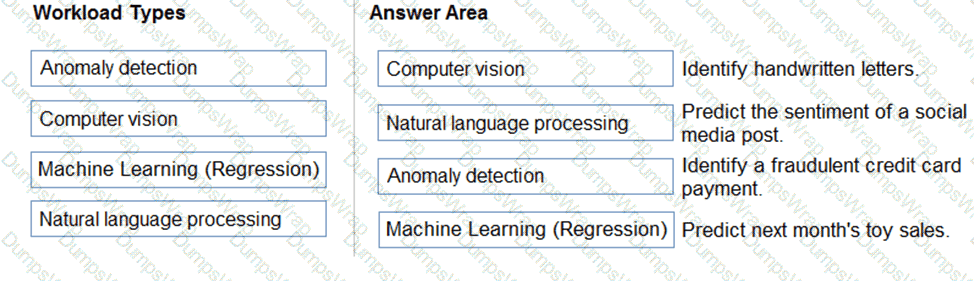
This question tests understanding of AI workload types, a fundamental topic in the Microsoft Azure AI Fundamentals (AI-900) curriculum. Each workload type—Computer Vision, Natural Language Processing, Machine Learning (Regression), and Anomaly Detection—serves a specific function within the AI landscape, as explained in Microsoft Learn’s module “Describe features of common AI workloads.”
Computer Vision enables computers to “see” and interpret visual information such as images or videos. Identifying handwritten letters requires analyzing image patterns, shapes, and strokes, which is a classic image recognition task. Azure’s Computer Vision API and Custom Vision services are specifically designed for such tasks.
Natural Language Processing (NLP) involves interpreting human language, both written and spoken. Determining the sentiment of a social media post (positive, negative, or neutral) is a typical text analytics use case within NLP, often implemented using Azure’s Text Analytics for Sentiment Analysis.
Anomaly Detection focuses on identifying data points that deviate from normal patterns. Detecting fraudulent credit card payments requires finding transactions that are unusual compared to historical spending behavior. Azure’s Anomaly Detector API applies machine learning to identify such irregularities.
Machine Learning (Regression) is used for predicting continuous numerical outcomes based on historical data. Estimating next month’s toy sales is a regression problem—an example of supervised learning where the model predicts future sales values from past sales data.
Thus, based on Microsoft’s official AI-900 learning objectives, the correct mapping of workloads to scenarios is:
Computer Vision → Identify handwritten letters
NLP → Predict sentiment
Anomaly Detection → Fraud detection
Machine Learning (Regression) → Predict toy sales
Which metric can you use to evaluate a classification model?
Options:
true positive rate
mean absolute error (MAE)
coefficient of determination (R2)
root mean squared error (RMSE)
Answer:
AExplanation:
For evaluating a classification model, the appropriate metric from the options provided is the True Positive Rate (TPR), also known as Sensitivity or Recall. According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Evaluate model performance”, classification models are evaluated using metrics that measure how accurately the model predicts categorical outcomes such as “yes/no,” “spam/not spam,” or “approved/denied.”
The True Positive Rate measures the proportion of correctly identified positive cases out of all actual positive cases. Mathematically, it is expressed as:
True Positive Rate (Recall)=True PositivesTrue Positives + False Negatives\text{True Positive Rate (Recall)} = \frac{\text{True Positives}}{\text{True Positives + False Negatives}}True Positive Rate (Recall)=True Positives + False NegativesTrue Positives
This metric is important when missing positive predictions carries a high cost, such as in medical diagnosis or fraud detection. Microsoft Learn highlights classification evaluation metrics such as accuracy, precision, recall, F1 score, and AUC (Area Under the Curve) as suitable for classification models.
The other options—Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and Coefficient of Determination (R²)—are regression metrics used to evaluate models that predict numeric values rather than categories. For example, they apply to predicting house prices or temperatures, not yes/no decisions.
Therefore, the correct classification evaluation metric among the choices is A. True Positive Rate.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

In the Microsoft Azure AI Fundamentals (AI-900) curriculum, computer vision capabilities refer to artificial intelligence systems that can analyze and interpret visual content such as images and videos. The Azure AI Vision and Face API services provide pretrained models for detecting, recognizing, and analyzing visual information, enabling developers to build intelligent applications that understand what they " see. "
When asked how computer vision capabilities can be deployed, the correct answer is to integrate a face detection feature into an app. This aligns with Microsoft Learn’s module “Describe features of computer vision workloads,” which explains that computer vision can identify objects, classify images, detect faces, and extract text (OCR). The Face API, a part of Azure AI Vision, specifically provides face detection, verification, and emotion recognition capabilities.
Integrating these services into an application allows it to perform actions such as:
Detecting human faces in photos or video streams.
Recognizing facial attributes like age, emotion, or head pose.
Enabling secure authentication based on face recognition.
The other options are incorrect because they relate to different AI workloads:
Develop a text-based chatbot for a website: This falls under Conversational AI, implemented with Azure Bot Service or Conversational Language Understanding (CLU).
Identify anomalous customer behavior on an online store: This task relates to machine learning and anomaly detection models, not computer vision.
Suggest automated responses to incoming email: This uses Natural Language Processing (NLP) capabilities, not visual analysis.
Therefore, the correct and Microsoft-verified completion of the statement is:
“Computer vision capabilities can be deployed to integrate a face detection feature into an app.”
Match the Al workload to the appropriate task.
To answer, drag the appropriate Ai workload from the column on the left to its task on the right. Each workload may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.
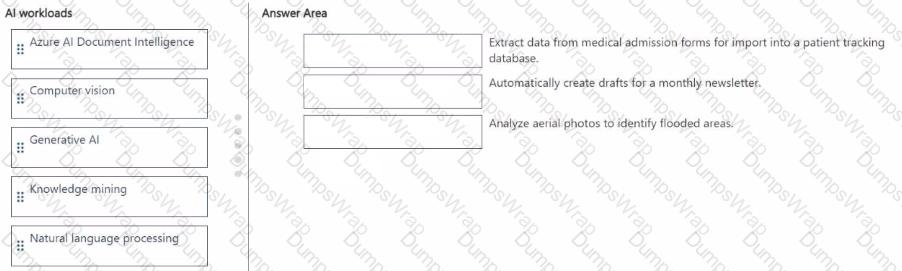
Options:
Answer:

Explanation:

This question tests your understanding of AI workloads as described in the Microsoft Azure AI Fundamentals (AI-900) study guide. Each Azure AI workload is designed to handle specific types of data and tasks: text, images, documents, or content generation.
Extract data from medical admission forms for import into a patient tracking database → Azure AI Document IntelligenceFormerly known as Form Recognizer, this service belongs to the Azure AI Document Intelligence workload. It extracts key-value pairs, tables, and textual information from structured and semi-structured documents such as forms, invoices, and admission sheets. For medical forms, Document Intelligence can identify fields like patient name, admission date, and diagnosis and export them into structured formats for database import.
Automatically create drafts for a monthly newsletter → Generative AIThis task involves creating original written content, which is a capability of Generative AI. Microsoft’s Azure OpenAI Service uses large language models (like GPT-4) to generate human-like text, summaries, or articles. Generative AI workloads are ideal for automating creative writing, drafting newsletters, producing blogs, or summarizing reports.
Analyze aerial photos to identify flooded areas → Computer VisionComputer Vision workloads involve analyzing and interpreting visual data from images or videos. This includes detecting objects, classifying scenes, and identifying patterns such as flooded regions in aerial imagery. Azure’s Computer Vision or Custom Vision services can be trained to detect water coverage or terrain changes using image recognition techniques.
Thus, the correct matches are:
Azure AI Document Intelligence → Extract medical form data
Generative AI → Create newsletter drafts
Computer Vision → Identify flooded areas from aerial photos
You plan to build a conversational Al solution that can be surfaced in Microsoft Teams. Microsoft Cortana, and Amazon Alexa. Which service should you use?
Options:
Azure Bot Service
Azure Cognitive Search
Language service
Speech
Answer:
AExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Describe features of conversational AI workloads on Azure,” the Azure Bot Service is the dedicated Azure service for building, connecting, deploying, and managing conversational AI experiences across multiple channels — such as Microsoft Teams, Cortana, and Amazon Alexa.
The Azure Bot Service integrates with the Bot Framework SDK to design intelligent chatbots that can communicate with users in natural language. It also connects seamlessly with other Azure Cognitive Services, such as Language Service (LUIS) for intent understanding and Speech Service for voice input/output.
The question specifies that the conversational AI must be accessible through multiple platforms, including Microsoft Teams, Cortana, and Alexa. Azure Bot Service supports this multi-channel communication model out of the box, allowing developers to configure a single bot that interacts through many endpoints simultaneously.
Other options:
B. Azure Cognitive Search: Used for information retrieval and knowledge mining, not conversational AI.
C. Language Service: Provides natural language understanding, key phrase extraction, sentiment analysis, etc., but doesn’t handle multi-channel communication.
D. Speech: Provides speech-to-text and text-to-speech conversion but is not a chatbot platform.
Therefore, the best solution for building and deploying a multi-channel conversational AI system is Azure Bot Service, as clearly defined in Microsoft’s AI-900 learning content.
You have an app that identifies birds in images. The app performs the following tasks:
* Identifies the location of the birds in the image
* Identifies the species of the birds in the image
Which type of computer vision does each task use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure,” there are multiple types of computer vision tasks, each designed for different goals such as recognizing, categorizing, or locating objects within an image.
In this question, the application performs two distinct tasks: locating birds within an image and identifying their species. Each of these corresponds to a different type of computer vision capability.
Locate the birds → Object detection
Object detection is used when an AI system needs to identify and locate multiple objects within a single image.
It not only recognizes what the object is but also provides bounding boxes that indicate the exact position of each object.
In this scenario, locating the birds (drawing rectangles around each bird) is achieved through object detection models, such as those available in the Azure Custom Vision Object Detection domain.
Identify the species of the birds → Image classification
Image classification focuses on identifying what is in the image rather than where it is.
It assigns a single label (or multiple labels in multilabel classification) to an entire image based on its contents.
In this case, determining the species of a bird (e.g., robin, eagle, parrot) is achieved through image classification, where the model compares visual features against learned patterns from training data.
Incorrect options:
Automated captioning generates descriptive sentences about an image, not object locations or classifications.
Optical character recognition (OCR) extracts text from images, irrelevant in this case.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

The correct completion of the sentence is:
“The interactive answering of questions entered by a user as part of an application is an example of natural language processing.”
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials, Natural Language Processing (NLP) is a branch of Artificial Intelligence that focuses on enabling computers to understand, interpret, and respond to human language in a way that is both meaningful and useful. It is one of the key AI workloads described in the “Describe features of common AI workloads” module on Microsoft Learn.
When a user types a question into an application and the system responds interactively — such as in a chatbot, Q & A system, or virtual assistant — this process requires language understanding. NLP allows the system to process the input text, determine user intent, extract relevant entities, and generate an appropriate response. This is the foundational capability behind services such as Azure Cognitive Service for Language, Language Understanding (LUIS), and QnA Maker (now integrated as Question Answering in the Language service).
Microsoft’s study guide explains that NLP workloads include the following key scenarios:
Language understanding: Determining intent and context from text or speech.
Text analytics: Extracting meaning, key phrases, sentiment, or named entities.
Conversational AI: Powering bots and virtual agents to interact using natural language.These systems rely on NLP models to analyze user inputs and respond accordingly.
In contrast:
Anomaly detection identifies data irregularities.
Computer vision analyzes images or video.
Forecasting predicts future values based on historical data.
Therefore, based on the AI-900 official materials, the interactive answering of user questions through an application clearly falls under Natural Language Processing (NLP).
Your company manufactures widgets.
You have 1.000 digital photos of the widgets.
You need to identify the location of the widgets within the photos.
What should you use?
Options:
Computer Vision Spatial Analysis
Custom Vision object detection
Custom Vision classification
Computer Vision Image Analysis
Answer:
BExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure,” object detection is a computer vision technique used to locate and identify objects within an image. It not only determines what objects are present but also where they appear in the image by returning bounding box coordinates around each detected item.
In this scenario, the goal is to identify the location of widgets within digital photos. This requires both recognition (knowing that the object is a widget) and localization (determining its position). The Custom Vision service in Azure allows you to train a model specifically for your own images, making it ideal for recognizing company-specific products such as widgets. By selecting the Object Detection domain in Custom Vision, you can label regions of interest in your training images. The model then learns to detect and locate those objects in new photos.
Let’s examine the other options:
A. Computer Vision Spatial Analysis: Used for people tracking, movement detection, and occupancy analytics in video streams — not for locating products in still images.
C. Custom Vision classification: This model categorizes an image as a whole (e.g., “contains a widget” or “does not contain a widget”) but does not locate objects within the image.
D. Computer Vision Image Analysis: Provides general image tagging, description, and OCR capabilities but does not pinpoint object locations.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

In Azure OpenAI Service, the temperature parameter directly controls the creativity and determinism of responses generated by models such as GPT-3.5. According to the Microsoft Learn documentation for Azure OpenAI models, temperature is a numeric value (typically between 0.0 and 2.0) that determines how “random” or “deterministic” the output should be.
A lower temperature value (for example, 0 or 0.2) makes the model’s responses more deterministic, meaning the same prompt consistently produces nearly identical outputs.
A higher temperature value (for example, 0.8 or 1.0) encourages creativity and variety, causing the model to generate different phrasing or interpretations each time it responds.
When a question specifies the need for more deterministic responses, Microsoft’s guidance is to decrease the temperature parameter. This adjustment makes the model focus on the most probable tokens (words) rather than exploring less likely options, improving reliability and consistency—ideal for business or technical applications where consistent answers are essential.
The other parameters serve different purposes:
Frequency penalty reduces repetition of the same phrases but does not control randomness.
Max response (max tokens) limits the maximum length of the generated output.
Stop sequence defines specific tokens that tell the model when to stop generating text.
Thus, the correct and Microsoft-verified completion is:
“You can modify the Temperature parameter to produce more deterministic responses from a chat solution that uses the Azure OpenAI GPT-3.5 model.”
You have a database that contains a list of employees and their photos.
You are tagging new photos of the employees.
For each of the following statements select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

These answers are derived from the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure.” The Azure Face service, part of Azure Cognitive Services, provides advanced facial recognition capabilities including detection, verification, identification, grouping, and similarity analysis.
Let’s analyze each statement:
“The Face service can be used to group all the employees who have similar facial characteristics.” → YesThe Face service supports a grouping function that automatically organizes a collection of unknown faces into groups based on visual similarity. It doesn’t require labeled data; instead, it identifies clusters of similar-looking faces. This is particularly useful when building or validating datasets of people.
“The Face service will be more accurate if you provide more sample photos of each employee from different angles.” → YesAccording to Microsoft documentation, model accuracy improves when you provide multiple high-quality images of each person under different conditions—such as varying lighting, poses, and angles. This diversity allows the service to better learn unique facial characteristics and improves recognition reliability, especially for identification and verification tasks.
“If an employee is wearing sunglasses, the Face service will always fail to recognize the employee.” → NoThis is incorrect. While occlusions (like sunglasses or hats) can reduce accuracy, the service may still recognize the person depending on how much of the face remains visible. Microsoft Learn explicitly notes that partial occlusion affects recognition confidence but does not guarantee failure.
In conclusion, the Face service can group similar faces (Yes), become more accurate with diverse samples (Yes), and still recognize partially covered faces though with lower confidence (No). These principles align directly with the Face API’s core functions and AI-900 learning objectives regarding computer vision and responsible AI-based facial recognition.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:
Privacy and security.
According to Microsoft’s Responsible AI Principles, implementing filters to block harmful or inappropriate content in a Generative AI chat solution demonstrates a commitment to the Privacy and Security principle. This principle ensures that AI systems are designed and operated in a way that protects users, their data, and society from harm.
When a chat system uses Generative AI models (like Azure OpenAI’s GPT-based services), there is a risk that the model might produce unsafe, offensive, or sensitive content. Microsoft addresses this through content filters and safety systems, which automatically detect and block violent, hate-based, or sexually explicit outputs. This is part of responsible deployment practices to ensure that user interactions remain safe, private, and compliant with ethical standards.
Implementing these filters aligns with the Privacy and Security principle because it:
Protects users from exposure to harmful or abusive content.
Ensures that conversations are safeguarded against malicious or unsafe use.
Upholds user trust by maintaining a safe digital environment for all participants.
Let’s briefly clarify why the other options are incorrect:
Fairness deals with ensuring unbiased treatment and equitable outcomes in AI decisions.
Transparency focuses on explaining how AI systems make decisions.
Accountability refers to human oversight and responsibility for AI actions.
Thus, content filtering mechanisms are explicitly an example of Privacy and Security, as they protect users and data from harm or misuse while maintaining ethical AI behavior.
Therefore, the verified correct answer is Privacy and security.
You need to count the number of animals in a photograph. Which type of computer vision should you use?
Options:
facial detection
image classification
optical character recognition (OCR)
object detection
Answer:
DExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) curriculum, computer vision encompasses several key capabilities: image classification, object detection, facial detection, and optical character recognition (OCR). When the task requires counting the number of distinct objects (in this case, animals) in an image, object detection is the correct type of vision model.
Object detection not only classifies what is present in an image but also identifies where each object appears by drawing bounding boxes around them. Each detected object is individually labeled, enabling the system to count or track them accurately. In contrast, image classification would only tell you the overall category (e.g., “This is an image of animals”) without counting how many animals are present.
Facial detection focuses solely on identifying human faces, while OCR extracts text from images — neither applies here.
Therefore, the AI-900 official learning modules confirm that object detection is the appropriate solution for identifying and counting multiple entities within an image.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:
< A webchat bot can interact with users visiting a website → Yes
Automatically generating captions for pre-recorded videos is an example of conversational AI → No
A smart device in the home that responds to questions such as “What will the weather be like today?” is an example of conversational AI → Yes
\ These answers are based on the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore conversational AI in Microsoft Azure.”
1. A webchat bot can interact with users visiting a website → Yes
This statement is true. A webchat bot is a key example of conversational AI, which allows users to communicate with an intelligent system through natural language. The Azure Bot Service supports a webchat channel, enabling website visitors to ask questions or get assistance directly through a chat interface embedded on a webpage. This allows businesses to provide 24/7 automated support and interactive engagement without human intervention.
2. Automatically generating captions for pre-recorded videos is an example of conversational AI → No
This is incorrect because automatically generating captions involves speech-to-text transcription, which falls under speech recognition and not conversational AI. While it uses AI to convert audio into text, it does not involve interactive communication or natural language dialogue. This task would be handled by Azure AI’s Speech service, not the conversational AI framework.
3. A smart device in the home that responds to questions such as “What will the weather be like today?” is an example of conversational AI → Yes
This is true. Smart assistants like those found in home devices (e.g., voice-activated systems) use conversational AI technologies to process spoken language (using natural language processing and speech recognition) and generate appropriate responses. This interaction represents a classic example of conversational AI, as it allows human-like dialogue between a user and an AI system.
✅ Final Answers:
Webchat bot interacting with users → Yes
Auto-captioning videos → No
Smart home device answering questions → Yes
Match the Al workload to the appropriate task.
To answer, drag the appropriate Al workload from the column on the left to its task on the right. Each workload may be used once, more than once, or not at all
NOTE: Each correct match is worth one point.
Options:
Answer:

You need to develop a mobile app for employees to scan and store their expenses while travelling.
Which type of computer vision should you use?
Options:
semantic segmentation
image classification
object detection
optical character recognition (OCR)
Answer:
DExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Explore computer vision”, Optical Character Recognition (OCR) is a form of computer vision that enables a system to detect and extract printed or handwritten text from images or documents. OCR is particularly useful in scenarios where the goal is to digitize textual information from physical documents, such as receipts, invoices, or travel expense forms — exactly as described in this question.
In the given scenario, employees need a mobile application that allows them to scan and store expenses while traveling. The process involves taking photos of receipts that contain printed text, such as vendor names, totals, dates, and item descriptions. The OCR technology automatically detects the text areas within the image and converts them into machine-readable and searchable data that can be stored in a database or processed further for expense management.
Microsoft’s Azure Cognitive Services include the Computer Vision API and the Form Recognizer service, both of which use OCR technology. The Form Recognizer builds upon OCR by adding intelligent document understanding, enabling it to extract structured data from expense receipts automatically.
Other answer options are incorrect for the following reasons:
A. Semantic segmentation assigns labels to every pixel in an image, typically used in autonomous driving or medical imaging, not for text extraction.
B. Image classification identifies the overall category of an image (e.g., “This is a receipt”), but it does not extract the textual content.
C. Object detection identifies and locates objects in an image with bounding boxes but is not used for text reading or conversion.
Therefore, based on the official AI-900 training and Microsoft Learn content, the correct answer is D. Optical Character Recognition (OCR) — the technology that enables extracting textual information from scanned expense receipts.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and the Microsoft Learn module “Describe Azure Machine Learning and Automated ML,” Azure Machine Learning designer (formerly known as Azure Machine Learning Studio) is a drag-and-drop, low-code/no-code environment that allows users to create, train, and evaluate machine learning models visually — without the need for extensive programming knowledge.
The designer provides a visual interface, known as the canvas, where users can:
Import and prepare data using modules for data transformation and cleaning.
Split data into training and testing datasets.
Select and configure algorithms (classification, regression, or clustering).
Train and evaluate the model.
Deploy the model as a web service directly from the designer.
The official Microsoft Learn content emphasizes that “Azure Machine Learning designer enables users to build, test, and deploy models by adding and connecting prebuilt modules on a visual interface.” This allows business analysts, data professionals, and beginners to experiment with machine learning workflows without writing code.
By comparison:
Automatically performing common data preparation tasks refers to Automated ML, not the designer.
Automatically selecting an algorithm is also part of Automated ML, which optimizes models algorithmically.
Using a code-first notebook experience applies to Azure Machine Learning notebooks, intended for data scientists familiar with Python and SDKs.
Therefore, as per the AI-900 study guide and Microsoft Learn documentation, the verified and correct answer is:
✅ Adding and connecting modules on a visual canvas, which accurately describes how Azure Machine Learning designer operates.
You have a dataset that contains sales data and has defined labels for types of customers. You need to create a model to categorize customer types based on sales data. Which type of machine learning should you use?
Options:
Classification
Clustering
Regression
Answer:
AYou plan to deploy an Azure Machine Learning model by using the Machine Learning designer
Which four actions should you perform in sequence? To answer, move the appropriate actions from the list of actions to the answer area and arrange them in the correct order.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of common machine learning types”, the standard workflow for creating and deploying a machine learning model — especially within Azure Machine Learning Designer — follows a structured sequence of steps to ensure that the model is trained effectively and evaluated correctly.
Here’s the detailed breakdown of the correct order:
Import and prepare a dataset:This is always the first step in the machine learning lifecycle. The dataset is imported into Azure Machine Learning and cleaned or preprocessed. Preparation might include handling missing values, normalizing data, removing outliers, and encoding categorical variables. This ensures the dataset is ready for modeling.
Split the data randomly into training data and validation data:The dataset is then divided into two parts — the training set and the validation (or testing) set. Typically, around 70–80% of the data is used for training and 20–30% for validation. This step ensures that the model can be evaluated on unseen data later, preventing overfitting.
Train the model:During this stage, the machine learning algorithm learns patterns from the training data. Azure Machine Learning Designer provides multiple algorithms (classification, regression, clustering, etc.) that can be applied using “Train Model” components.
Evaluate the model against the validation dataset:Finally, the trained model’s performance is tested using the validation dataset. Evaluation metrics such as accuracy, precision, recall, or RMSE (depending on the model type) are calculated to assess how well the model generalizes to new data.
The incorrect option — “Evaluate the model against the original dataset” — is not used in proper ML workflows, because evaluating on the same data used for training would give misleadingly high accuracy due to overfitting.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

This question examines your understanding of Natural Language Processing (NLP) as described in the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Explore natural language processing.” NLP is a branch of artificial intelligence that enables computers to analyze, understand, and generate human language — both written and spoken. Typical NLP tasks include text analytics, language understanding, sentiment analysis, key phrase extraction, and profanity detection.
Monitoring online service reviews for profanities → YesThis is a classic example of NLP. Detecting profane or inappropriate words in customer reviews requires analyzing text content. Azure Cognitive Services offers Content Moderator and Text Analytics APIs that can detect and filter profanity, sentiment, and offensive language automatically. Microsoft Learn states: “Natural language processing is used to process and analyze text to detect sentiment, key phrases, and inappropriate content.” Hence, this task is correctly classified as NLP.
Identifying brand logos in an image → NoThis task belongs to Computer Vision, not NLP. The Computer Vision API and Custom Vision service in Azure are designed to detect and classify visual elements like logos, objects, or scenes. Since it involves images, not text, it is unrelated to natural language processing.
Monitoring public news sites for negative mentions of a product → YesThis is another valid example of NLP. The process involves analyzing the sentiment of text from online articles to determine whether mentions of a product are positive, neutral, or negative. Azure Text Analytics provides prebuilt sentiment analysis and entity recognition capabilities that help automate such monitoring.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

“The Azure OpenAI GPT-3.5 Turbo model can transcribe speech to text.” — NOThis statement is false. The GPT-3.5 Turbo model is a text-based large language model (LLM) designed for natural language understanding and generation, such as answering questions, summarizing text, or writing content. It does not process or transcribe audio input. Speech-to-text capabilities belong to Azure AI Speech Services, specifically the Speech-to-Text API, not Azure OpenAI.
“The Azure OpenAI DALL-E model generates images based on text prompts.” — YESThis statement is true. The DALL-E model, available within Azure OpenAI Service, is a generative AI model that creates original images from natural language descriptions (text prompts). For example, given a prompt like “a futuristic city at sunset,” DALL-E generates a unique, high-quality image representing that concept. This aligns with generative AI workloads in the AI-900 study guide, where DALL-E is specifically mentioned as an image-generation model.
“The Azure OpenAI embeddings model can convert text into numerical vectors based on text similarities.” — YESThis statement is also true. The embeddings model in Azure OpenAI converts text into multi-dimensional numeric vectors that represent semantic meaning. These embeddings enable tasks such as semantic search, recommendations, and text clustering by comparing similarity scores between vectors. Words or phrases with similar meanings have vectors close together in the embedding space.
In summary:
GPT-3.5 Turbo → Text generation (not speech-to-text)
DALL-E → Image generation from text prompts
Embeddings → Convert text into numerical semantic representations
Correct selections: No, Yes, Yes.
brectly completes the sentence.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of common AI workloads”, OCR (Optical Character Recognition) is a Computer Vision technology that detects and extracts printed or handwritten text from images and scanned documents. OCR allows organizations and individuals to convert physical or image-based text into machine-readable, editable, and searchable digital text.
In the context of this question, a historian working with old newspaper articles or archival documents would use OCR to digitize printed content. For instance, the historian can scan or photograph old newspaper pages, and then use an OCR tool—such as Azure Computer Vision’s OCR API—to automatically recognize and extract the textual content from those images. This process enables the historian to store, edit, and analyze the content digitally without manually typing everything.
OCR works by using deep learning algorithms trained on thousands of text samples. The system analyzes patterns, shapes, and spatial relationships of characters to identify text accurately, even from low-quality or aged paper documents. Once extracted, the digital text can be indexed, translated, or processed further using Natural Language Processing (NLP) tools for content analysis.
Now, addressing the other options:
Facial analysis is used to detect emotions, age, or gender from human faces—irrelevant to text digitization.
Image classification identifies entire images by categories (e.g., cat, car, flower).
Object detection identifies and locates multiple objects within an image but doesn’t extract text.
Therefore, per the AI-900 learning objectives under the Computer Vision workload, the correct and verified completion is:
Select the answer that correctly completes the sentence.

Options:
Answer:
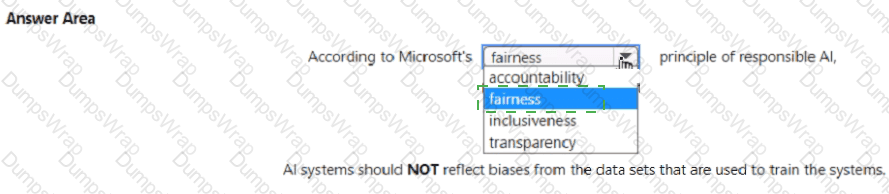
Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Identify guiding principles for responsible AI,” Fairness is one of Microsoft’s six core principles of Responsible AI. The principle of fairness ensures that AI systems treat all individuals and groups equitably, and that the models do not produce biased or discriminatory outcomes.
Bias in AI systems can occur when training data reflects existing prejudices, inequalities, or imbalances. For example, if a dataset used for a hiring model underrepresents a certain demographic group, the AI system might produce unfair recommendations. Microsoft emphasizes that AI should not reflect or reinforce bias and that developers must actively design, test, and monitor models to mitigate unfairness.
Microsoft’s Six Responsible AI Principles:
Fairness – AI systems should treat everyone equally and avoid bias.
Reliability and safety – AI systems must operate as intended even under unexpected conditions.
Privacy and security – AI must protect personal and business data.
Inclusiveness – AI should empower all people and be accessible to diverse users.
Transparency – AI systems should be understandable and their decisions explainable.
Accountability – Humans should be accountable for AI system outcomes.
The other options do not fit this context:
Accountability ensures human responsibility for AI decisions.
Inclusiveness focuses on accessibility and empowering all users.
Transparency relates to making AI systems understandable.
Therefore, the correct answer is fairness, as it directly addresses the principle that AI systems should NOT reflect biases from the datasets used to train them.
You have the following apps:
• App1: Uses a set of images of tumors to identify whether the tumors are benign or malignant and suggest a treatment
• App2: Uses images from cameras to track individual livestock as they move around a farm
• App3: Identifies brands in photographs of billboards
What does each app use? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

Options:
Answer:
Explanation:
Let’s analyze each application in the context of Microsoft Azure AI Fundamentals (AI-900) and computer vision model types.
App1 – Uses a set of images of tumors to identify whether the tumors are benign or malignant and suggest a treatment → Image classificationThis application is performing image classification, where each image (of a tumor) is assigned to a single predefined category — benign or malignant. Image classification models learn patterns from labeled training images and predict the correct class for new ones. In this case, the model identifies the type of tumor, a classic binary classification scenario.
App2 – Uses images from cameras to track individual livestock as they move around a farm → Object detectionThis scenario describes object detection, which not only identifies what objects (in this case, animals) are in an image but also locates them by drawing bounding boxes. Tracking movement requires detecting the position of each animal frame by frame. Object detection models are well-suited for use cases involving counting, tracking, or monitoring objects in a visual scene.
App3 – Identifies brands in photographs of billboards → Optical character recognition (OCR)This app involves reading and interpreting text (brand names, slogans, or logos) from images of billboards. Optical Character Recognition (OCR), part of Azure AI Vision, extracts textual information from images or scanned documents. Once extracted, that text can be analyzed to identify brand names or keywords.
Summary:
App1 → Image classification
App2 → Object detection
App3 → Optical character recognition (OCR)
What is a use case for classification?
Options:
predicting how many cups of coffee a person will drink based on how many hours the person slept the previous night.
analyzing the contents of images and grouping images that have similar colors
predicting whether someone uses a bicycle to travel to work based on the distance from home to work
predicting how many minutes it will take someone to run a race based on past race times
Answer:
CExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of classification machine learning”, classification is a type of supervised machine learning used when the goal is to predict a categorical outcome. That means the output variable represents discrete labels such as Yes/No, True/False, or Category A/B/C.
In this example, the model is predicting whether a person uses a bicycle (Yes or No) — a binary categorical outcome. The input (distance from home to work) is numeric, but the prediction is a class or category, which makes it a classification problem.
To compare:
A and D (predicting how many cups of coffee or race minutes) involve numeric predictions, which are regression tasks.
B (grouping images by similar colors) involves clustering, an unsupervised learning method used to find natural groupings in data.
Thus, the use case that fits classification is predicting whether someone uses a bicycle, since the answer is categorical.
Match the Azure Cognitive Services to the appropriate Al workloads.
To answer, drag the appropriate service from the column on the left to its workload on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Options:
Answer:

Explanation:

The correct matches are Custom Vision, Form Recognizer, and Face — each corresponding to a distinct capability under Azure Cognitive Services as described in the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn modules on Computer Vision workloads.
Custom Vision → Identify objects in an imageThe Custom Vision service is part of the Azure Cognitive Services suite that enables developers to train custom image classification and object detection models. Unlike the prebuilt Computer Vision API, Custom Vision allows users to upload their own labeled images and teach the model to recognize specific objects relevant to their business context. The AI-900 syllabus explains that Custom Vision is ideal for tasks such as identifying products on a shelf, categorizing images, or detecting defects in manufacturing.
Form Recognizer → Automatically import data from an invoice to a databaseForm Recognizer is a document processing AI service that extracts structured data from forms, receipts, and invoices. It uses optical character recognition (OCR) combined with layout and key-value pair detection to automatically capture information such as invoice numbers, amounts, and vendor names. The AI-900 study materials highlight this service under the Document Intelligence category, emphasizing its ability to streamline data entry and business automation workflows by importing extracted data directly into databases or applications.
Face → Identify people in an imageThe Face service provides advanced facial detection and recognition capabilities. It can locate faces in images, compare similarities between faces, identify known individuals, and even detect facial attributes such as age or emotion. The AI-900 course classifies this under Computer Vision services for person identification and security-related use cases such as access control or identity verification.
Thus, each mapping aligns precisely with the AI-900 official learning outcomes on Cognitive Services capabilities:
Custom Vision → Object recognition
Form Recognizer → Data extraction from forms
Face → People identification
✅ Final verified configuration:
Custom Vision → Identify objects in an image
Form Recognizer → Automatically import data from an invoice to a database
Face → Identify people in an image
Which OpenAI model does GitHub Copilot use to make suggestions for client-side JavaScript?
Options:
GPT-4
Codex
DALL-E
GPT-3
Answer:
BExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) learning path and Microsoft Learn documentation on GitHub Copilot, GitHub Copilot is powered by OpenAI Codex, a specialized language model derived from the GPT-3 family but fine-tuned specifically on programming languages and code data.
OpenAI Codex was designed to translate natural language prompts into executable code in multiple programming languages, including JavaScript, Python, C#, TypeScript, and Go. It can understand comments, function names, and code structure to generate relevant code suggestions in real time.
When a developer writes client-side JavaScript, GitHub Copilot uses Codex to analyze the context of the file and generate intelligent suggestions, such as completing functions, writing boilerplate code, or suggesting improvements. Codex can also explain what specific code does and provide inline documentation, which enhances developer productivity.
Option A (GPT-4): While some newer versions of GitHub Copilot (Copilot X) may integrate GPT-4 for conversational explanations, the core code completion engine remains based on Codex, as per the AI-900-level content.
Option C (DALL-E): Used for image generation, not for programming tasks.
Option D (GPT-3): Codex was fine-tuned from GPT-3 but has been further trained specifically for code generation tasks.
Therefore, the verified and official answer from Microsoft’s AI-900 curriculum is B. Codex — the OpenAI model used by GitHub Copilot to make suggestions for client-side JavaScript and other programming languages.
You plan to deploy an Azure Machine Learning model as a service that will be used by client applications.
Which three processes should you perform in sequence before you deploy the model? To answer, move the appropriate processes from the list of processes to the answer area and arrange them in the correct order.

Options:
Answer:
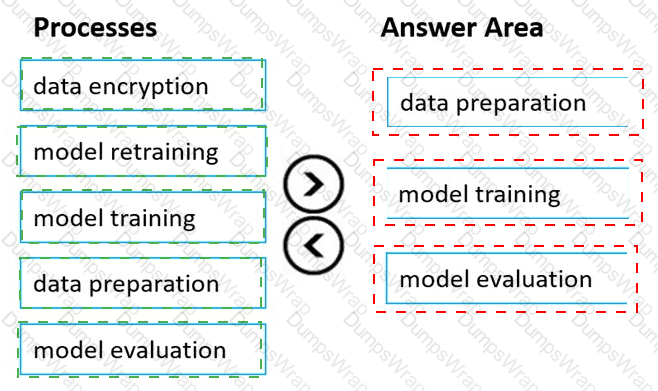
Explanation:

The correct order of processes before deploying a model as a service is:
(1) Data preparation → (2) Model training → (3) Model evaluation.
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Explore the machine learning process”, machine learning follows a structured lifecycle that involves several sequential stages. Before a model can be deployed, the data must be properly prepared, the model must be trained, and then its performance must be evaluated to ensure accuracy and reliability.
Data Preparation:The first stage involves collecting, cleaning, and transforming raw data into a usable format. Azure Machine Learning provides tools like Data Wrangler, Data Labeling, and Data Transformation pipelines to ensure the dataset is accurate and consistent. As per Microsoft Learn, “data preparation is essential to remove noise, handle missing values, and split the dataset into training and testing sets.” This step ensures the model learns from quality input.
Model Training:In this step, algorithms are applied to the prepared training data to create a predictive model. The system learns patterns and relationships from the data. Azure Machine Learning allows model training using AutoML, custom code, or designer pipelines. The training process produces a model that can make predictions, but it still needs to be tested before deployment.
Model Evaluation:Once trained, the model’s performance is tested against unseen (test) data. Evaluation metrics like accuracy, precision, recall, and F1-score are analyzed to verify if the model meets business and performance requirements. Microsoft Learn defines this stage as “assessing the model’s performance to determine its readiness for deployment.”
After these three processes, the model can then be deployed as a web service using Azure Machine Learning endpoints. Model retraining happens later when new data becomes available, and data encryption is a security process, not part of model development steps.
For each of the following statements, select Yes if the statement is True. Otherwise, select No. NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:
< Smart home device answering questions → Yes
Webchat using Azure Bot Service → Yes
Auto-caption generation for videos → No
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe features of common AI workloads”, Conversational AI refers to systems designed to engage in human-like dialogue through natural language—either text or speech. These systems include chatbots, virtual assistants, and voice-enabled smart devices, all of which can interpret user intent and respond meaningfully.
A smart device in the home that responds to questions such as “When is my next appointment?” – Yes.This is a classic example of Conversational AI. Devices like smart speakers or personal digital assistants use speech recognition, natural language understanding (NLU), and language generation to interpret spoken input and respond conversationally. The AI-900 study materials identify these as examples of voice-based conversational AI systems, which fall under the Speech and Language AI workloads.
An interactive webchat feature on a company website can be implemented by using Azure Bot Service – Yes.This statement is true. The Azure Bot Service is the primary Microsoft tool for creating and deploying conversational bots across various channels, including websites, Microsoft Teams, and other messaging platforms. The AI-900 syllabus specifically cites this as an example of implementing conversational AI for customer support or information retrieval.
Automatically generating captions for pre-recorded videos is an example of conversational AI – No.This is not conversational AI; instead, it falls under the Speech AI workload, specifically speech-to-text transcription. Automatically generating captions involves converting audio from video into written text but does not involve dialogue or interaction between a user and a system.
Thus, based on the official AI-900 guidance, only the first two scenarios describe conversational AI use cases.
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Explore fundamental principles of machine learning”, regression models are used to predict numerical or continuous values based on patterns found in historical data. When the goal is to forecast or estimate a real-valued outcome—such as price, temperature, sales, or age—the appropriate model type is regression.
In this question, the task is to predict the sale price of auctioned items. Since price is a continuous numeric value that can vary within a range (for example, $100.50, $105.75, $120.00, etc.), it fits perfectly into a regression problem. Microsoft Learn defines regression as “a supervised machine learning technique that predicts a numeric value based on relationships found in input features.” Common regression algorithms include linear regression, decision tree regression, and neural network regression.
By contrast:
Classification is used when the output variable represents categories or classes, such as predicting whether an email is spam or not spam, or whether a transaction is fraudulent or legitimate. Classification predicts discrete labels, not continuous values.
Clustering, on the other hand, is an unsupervised learning method used to group similar data points together without predefined labels. Examples include grouping customers by purchasing behavior or grouping images by visual similarity.
In a predictive business scenario, like estimating the price of an auctioned item based on features such as age, condition, and demand, regression models are most appropriate. Azure Machine Learning supports regression experiments using built-in algorithms and AutoML to automatically choose the best-performing model for continuous output prediction.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure,” computer vision is a field of artificial intelligence that enables computers to interpret and understand visual information from the world — such as images or videos.
In this scenario, the task is to count the number of animals in an area based on a video feed. This requires the system to:
Detect the presence of animals in each frame of the video (object detection).
Track and count them across multiple frames as they move.
These are classic computer vision tasks, as they involve analyzing visual inputs (video or image data) and identifying objects (in this case, animals). Azure provides services such as Azure Computer Vision, Custom Vision, and Video Indexer, which can perform object detection, counting, and activity recognition using AI models trained on visual datasets.
Why the other options are incorrect:
Forecasting: Involves predicting future values based on historical data (e.g., predicting sales or weather), not analyzing video feeds.
Knowledge mining: Focuses on extracting insights from large text-based document repositories, not images or videos.
Anomaly detection: Identifies unusual patterns in numeric or time-series data, not visual objects.
Therefore, identifying and counting animals in video footage falls under computer vision, since it uses AI to visually detect, classify, and quantify objects in real-time or recorded feeds.
You have an Al solution that provides users with the ability to control smart devices by using verbal commands.
Which two types of natural language processing (NLP) workloads does the solution use? Each correct answer presents part of the solution.
NOTE: Each correct selection is worth one point.
Options:
text-to-speech
translation
language modeling
key phrase extraction
speech-to-text
Answer:
C, EExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and the Microsoft Learn module “Describe features of Natural Language Processing (NLP) workloads on Azure”, this scenario combines two major capabilities of AI: speech recognition and natural language understanding.
Speech-to-Text (E) – This is the first step in processing verbal commands. The Azure Speech service converts the spoken words of a user into textual data that can be understood and processed by downstream components. This workload is commonly referred to as speech recognition, and it falls under the speech capabilities of Azure Cognitive Services. Without this transcription process, the system could not interpret the user’s voice input.
Language Modeling (C) – After the speech input is converted into text, the next step is to interpret the meaning of the text so the system can take appropriate action. Language modeling, also known as language understanding, is responsible for identifying the user’s intent (for example, “turn on the lights” or “set the thermostat to 72 degrees”) and extracting entities (such as device name or temperature value). In Azure, this function is handled by Language Understanding (LUIS) or Conversational Language Understanding (CLU). These models allow smart systems to process commands and map them to defined actions.
Other options are not correct:
A. Text-to-speech converts text output into spoken language, which is not mentioned as a requirement.
B. Translation converts text from one language to another, irrelevant to this scenario.
D. Key phrase extraction identifies important terms in text but doesn’t interpret or execute commands.
Therefore, the solution uses speech-to-text to transcribe verbal commands and language modeling to understand and act upon them — the two key NLP workloads enabling voice-controlled smart devices.
You are processing photos of runners in a race.
You need to read the numbers on the runners’ shirts to identity the runners in the photos.
Which type of computer vision should you use?
Options:
facial recognition
optical character recognition (OCR)
semantic segmentation
object detection
Answer:
BExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of computer vision workloads”, Optical Character Recognition (OCR) is a core capability within the computer vision domain that enables systems to detect and extract text from images or documents. OCR technology can identify printed or handwritten characters in photographs, scanned documents, or camera feeds, and convert them into machine-readable text.
In this scenario, the task is to read the numbers on runners’ shirts in race photos. These numbers are textual or numeric characters embedded within images. OCR is specifically designed for this purpose — to locate and recognize characters within visual data and convert them into usable text. Once extracted, those numbers can be cross-referenced with a database to identify each runner.
Let’s analyze why the other options are incorrect:
A. Facial recognition focuses on identifying individuals based on unique facial features, not reading text or numbers.
C. Semantic segmentation classifies each pixel of an image into categories (for example, separating road, sky, and people), but it doesn’t read text.
D. Object detection identifies and locates objects within an image (such as detecting people or vehicles) but does not extract readable text or numbers.
Therefore, since the task involves reading textual or numeric content from an image, the appropriate type of computer vision to use is Optical Character Recognition (OCR).
What are two metrics that you can use to evaluate a regression model? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Options:
coefficient of determination (R2)
F1 score
root mean squared error (RMSE)
area under curve (AUC)
balanced accuracy
Answer:
A, CExplanation:
A: R-squared (R2), or Coefficient of determination represents the predictive power of the model as a value between -inf and 1.00. 1.00 means there is a perfect fit, and the fit can be arbitrarily poor so the scores can be negative.
C: RMS-loss or Root Mean Squared Error (RMSE) (also called Root Mean Square Deviation, RMSD), measures the difference between values predicted by a model and the values observed from the environment that is being modeled.
You have a dataset that contains the columns shown in the following table.
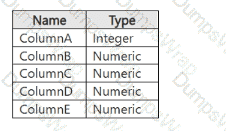
You have a machine learning model that predicts the value of ColumnE based on the other numeric columns.
Which type of model is this?
Options:
regression
analysis
clustering
Answer:
AExplanation:
The dataset described contains numeric columns (ColumnA through ColumnE). The model’s task is to predict the value of ColumnE based on the other numeric columns (A–D). This is a classic regression problem.
According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn module “Identify common types of machine learning,” a regression model is used when the target variable (the value to predict) is continuous and numeric, such as price, temperature, or—in this case—a numerical value in ColumnE.
Regression models analyze relationships between independent variables (inputs: Columns A–D) and a dependent variable (output: ColumnE) to predict a continuous outcome. Common regression algorithms include linear regression, decision tree regression, and neural network regression.
Option analysis:
A. Regression: ✅ Correct. Used for predicting numerical, continuous values.
B. Analysis: ❌ Incorrect. “Analysis” is a general term, not a machine learning model type.
C. Clustering: ❌ Incorrect. Clustering is unsupervised learning, grouping similar data points, not predicting values.
Therefore, the type of machine learning model used to predict ColumnE (a numeric value) from other numeric columns is Regression, which fits perfectly within Azure’s supervised learning models.
You have a website that includes customer reviews.
You need to store the reviews in English and present the reviews to users in their respective language by recognizing each user’s geographical location.
Which type of natural language processing workload should you use?
Options:
translation
language modeling
key phrase extraction
speech recognition
Answer:
AExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) syllabus and Microsoft Learn module “Describe features of natural language processing (NLP) workloads on Azure,” translation is a core NLP workload that converts text from one language into another while maintaining meaning and context.
In this scenario, the website stores reviews in English and must present them in the user’s native language based on geographical location. This directly requires a translation workload, which uses Azure Cognitive Services — specifically, the Translator service — to automatically translate content dynamically for each user.
Other options explained:
B. Language modeling involves predicting the next word in a sentence or understanding linguistic patterns; it’s used in model training, not translation.
C. Key phrase extraction identifies main ideas in text, not language conversion.
D. Speech recognition converts spoken words into written text but does not perform translation or handle geographic adaptation.
Microsoft’s Translator service supports real-time text translation, multi-language detection, and context preservation, making it ideal for global websites. The AI-900 study guide emphasizes translation as one of the most common NLP workloads, enabling applications to break language barriers and enhance accessibility for diverse audiences.
Therefore, based on official Microsoft Learn material, the correct answer is:
✅ A. translation.
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:

Explanation:
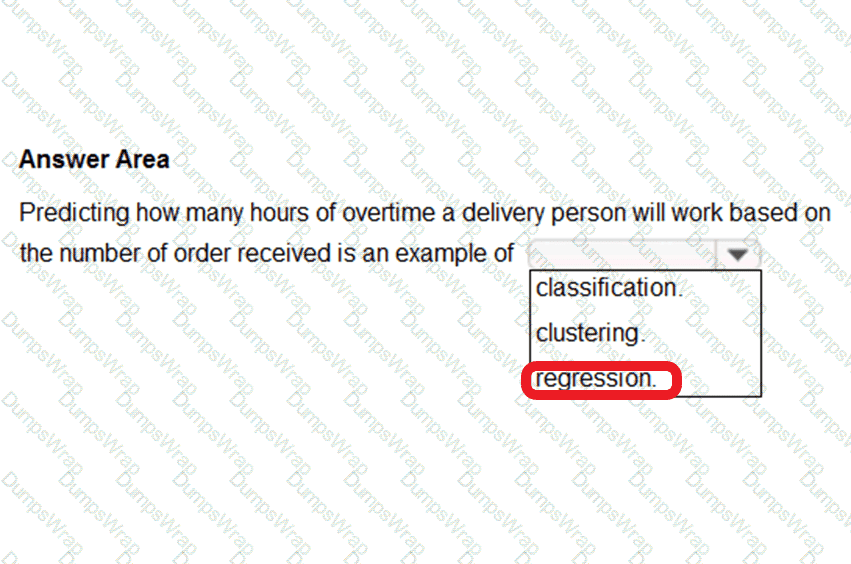
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Identify features of regression machine learning”, regression is a type of supervised machine learning used when the target variable (the value you want to predict) is a continuous numeric value.
In this scenario, the task is to predict how many hours of overtime a delivery person will work based on the number of orders received. Both the input (number of orders) and the output (hours of overtime) are numeric variables. Since the goal is to estimate a quantitative value rather than categorize or group data, this is a classic example of a regression problem.
Regression models analyze the relationship between variables to make numerical predictions. For example, the model might learn that each additional 20 orders increases overtime by about two hours. Common algorithms used for regression include linear regression, decision tree regression, and boosted regression models. These models produce outputs such as “expected overtime = 5.6 hours,” which are continuous numeric results.
To contrast with the other options:
Classification is used for predicting categories or labels, such as “overtime required” vs. “no overtime,” or “high-risk” vs. “low-risk.” It deals with discrete outputs rather than continuous numbers.
Clustering is an unsupervised learning approach used to group similar data points based on shared characteristics, such as grouping delivery staff by performance patterns or customer types.
As emphasized in Microsoft’s Responsible AI and Machine Learning Fundamentals learning paths, regression models are ideal for numeric forecasting problems such as predicting sales, revenue, demand, or working hours.
Therefore, the correct answer is: Regression.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

The correct answer is “An embedding.”
In the context of large language models (LLMs) such as GPT-3, GPT-3.5, or GPT-4, an embedding refers to a multi-dimensional numeric vector representation assigned to each word, token, or phrase. According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn documentation for Azure OpenAI embeddings, embeddings are used to represent textual or semantic meaning in a numerical form that a machine learning model can process mathematically.
Each embedding captures the semantic relationships between words. Words or tokens with similar meanings (for example, “car” and “automobile”) are represented by vectors that are close together in the multi-dimensional space, while unrelated words (like “tree” and “laptop”) are farther apart. This vector representation enables the model to understand context, similarity, and relationships between different pieces of text.
Embeddings are fundamental in tasks such as:
Semantic search: Finding documents or sentences with similar meaning.
Clustering: Grouping related concepts together.
Recommendation systems: Suggesting similar content based on text meaning.
Contextual understanding: Helping generative models produce coherent and context-aware text.
Option review:
Attention: A mechanism used within transformers to focus on relevant parts of input sequences but not a representation of words.
A completion: Refers to the generated text output from a model, not the internal representation.
A transformer: The architecture that powers models like GPT, not the vector representation of tokens.
Therefore, the correct term for a multi-dimensional vector assigned to each word or token in a large language model (LLM) is An embedding, which represents how meaning is numerically encoded and compared within language models.
You need to develop a web-based AI solution for a customer support system. Users must be able to interact with a web app that will guide them to the best resource or answer.
Which service should you integrate with the web app to meet the goal?
Options:
Azure Al Language Service
Face
Azure Al Translator
Azure Al Custom Vision
Answer:
DExplanation:
QnA Maker is a cloud-based API service that lets you create a conversational question-and-answer layer over your existing data. Use it to build a knowledge base by extracting questions and answers from your semistructured content, including FAQs, manuals, and documents. Answer users’ questions with the best answers from the QnAs in your knowledge base—automatically. Your knowledge base gets smarter, too, as it
continually learns from user behavior.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

In Microsoft Azure AI Language Service, both Named Entity Recognition (NER) and Key Phrase Extraction are core features for text analytics. They serve distinct purposes in analyzing and structuring unstructured text data.
Named Entity Recognition (NER):NER is used to identify and categorize specific entities within text, such as people, organizations, locations, dates, times, and quantities. According to Microsoft Learn’s “Analyze text with Azure AI Language” module, NER scans text to extract these entities along with their types. Therefore, the statement “Named entity recognition can be used to retrieve dates and times in a text string” is True (Yes).
Key Phrase Extraction:This feature identifies the most important phrases or main topics in a block of text. It is useful for summarization or highlighting central ideas without classifying them into specific categories. Therefore, the statement “Key phrase extraction can be used to retrieve important phrases in a text string” is also True (Yes).
City Name Retrieval:While key phrase extraction highlights major phrases, it does not extract specific entities like cities or dates. Extracting such details requires Named Entity Recognition, which is designed to find named entities such as city names, people, or organizations. Hence, the statement “Key phrase extraction can be used to retrieve all the city names in a text string” is False (No).
You need to implement a pre-built solution that will identify well-known brands in digital photographs. Which Azure Al sen/tee should you use?
Options:
Face
Custom Vision
Computer Vision
Form Recognizer
Answer:
CExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Azure,” the Computer Vision service can analyze images to detect objects, landmarks, celebrities, and brands.
The brand detection capability in the Computer Vision Image Analysis API uses pre-trained models to identify well-known brand logos within images. When an image is analyzed, the service returns brand names, confidence scores, and bounding box coordinates where the logos appear.
Let’s examine the other options:
A. Face: Detects and analyzes human faces, not brand logos.
B. Custom Vision: Used for training custom models to recognize unique objects (e.g., company-specific products), not pre-built brand detection.
D. Form Recognizer: Extracts text and data from structured or semi-structured documents like invoices and receipts.
Thus, since the question specifies identifying well-known brands using a pre-built AI model, the correct Azure service is Computer Vision.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

The correct answer is Azure AI Language, which includes the Question Answering capability (previously known as QnA Maker). According to the Microsoft Azure AI Fundamentals (AI-900) study guide and Microsoft Learn documentation, the Azure AI Language service can be used to create a knowledge base from frequently asked questions (FAQ) and other structured or semi-structured text sources.
This service allows developers to build intelligent applications that can understand and respond to user questions in natural language by referencing prebuilt or custom knowledge bases. The Question Answering feature extracts pairs of questions and answers from documents, websites, or manually entered data and uses them to construct a searchable knowledge base. This knowledge base can then be integrated with Azure Bot Service or other conversational platforms to create interactive, self-service chatbots.
Here’s how it works:
Developers upload FAQ documents, URLs, or structured content.
Azure AI Language processes the content and identifies logical question-answer pairs.
The model stores these pairs in a knowledge base that can be queried by user input.
When users ask questions, the model finds the best matching answer using natural language understanding techniques.
In contrast:
Azure AI Document Intelligence (Form Recognizer) is used to extract structured data from forms and documents, not to create FAQ knowledge bases.
Azure AI Bot Service is for managing and deploying conversational bots but does not generate knowledge bases.
Microsoft Bot Framework SDK provides tools for building conversational logic but still requires a knowledge source like Question Answering from Azure AI Language.
Therefore, the service that can create a knowledge base from FAQ content is Azure AI Language.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of common machine learning types”, there are three main types of machine learning: supervised learning, unsupervised learning, and reinforcement learning. Within supervised learning, two common approaches are regression and classification, while clustering is a primary example of unsupervised learning.
“You train a regression model by using unlabeled data.” – No.Regression models are trained with labeled data, meaning the input data includes both features (independent variables) and target labels (dependent variables) representing continuous numerical values. Examples include predicting house prices or sales forecasts. Unlabeled data (data without target output values) cannot be used to train regression models; such data is used in unsupervised learning tasks like clustering.
“The classification technique is used to predict sequential numerical data over time.” – No.Classification is used for categorical predictions, where outputs belong to discrete classes, such as spam/not spam or disease present/absent. Predicting sequential numerical data over time refers to time series forecasting, which is typically a regression or forecasting problem, not classification. The AI-900 syllabus clearly separates classification (categorical prediction) from regression (continuous value prediction) and time series (temporal pattern analysis).
“Grouping items by their common characteristics is an example of clustering.” – Yes.This statement is correct. Clustering is an unsupervised learning technique used to group similar data points based on their features. The AI-900 study materials describe clustering as the process of “discovering natural groupings in data without predefined labels.” Common examples include customer segmentation or document grouping.
Therefore, based on Microsoft’s AI-900 training objectives and definitions:
Regression → supervised learning using labeled continuous data (No)
Classification → categorical prediction, not sequential numeric forecasting (No)
Clustering → grouping by similarity (Yes)
You are designing a system that will generate insurance quotes automatically.
Match the Microsoft responsible Al principles to the appropriate requirements.
To answer, drag the appropriate principle from the column on the left to its requirement on the right Each principle may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Options:
Answer:

Explanation:

Microsoft’s Responsible AI principles are the foundation for developing and deploying ethical and trustworthy AI systems. The six key principles are Fairness, Reliability and Safety, Privacy and Security, Inclusiveness, Transparency, and Accountability. Each principle guides specific practices for ensuring AI systems operate responsibly in real-world applications like automated insurance quoting systems.
Transparency – This principle ensures that the AI’s decisions can be understood and explained. Recording the decision-making process and enabling staff to trace how a quote was generated aligns with transparency. It allows stakeholders to interpret the reasoning behind model outputs, ensuring that the AI behaves predictably and ethically.
Privacy and Security – This principle focuses on protecting personal data and ensuring that sensitive information is handled responsibly. Limiting access to customer data only to authorized personnel maintains compliance with privacy laws (like GDPR) and safeguards against misuse. Microsoft emphasizes that AI systems should maintain strict control over data visibility and integrity.
Inclusiveness – This principle ensures that AI systems are accessible to all users, including people with disabilities. By supporting screen readers and assistive technologies, the system ensures equal access to information and services for every customer. Inclusiveness prevents discrimination and promotes accessibility, both of which are central to Microsoft’s Responsible AI strategy.
Thus, the correct mapping of principles is:
Decision process → Transparency
Personal information visibility → Privacy and Security
Accessibility via screen readers → Inclusiveness.
Which feature of the Azure Al Language service should you use to automate the masking of names and phone numbers in text data?
Options:
Personally Identifiable Information (Pll) detection
entity linking
custom text classification
custom named entity recognition (NER)
Answer:
AExplanation:
The correct answer is A. Personally Identifiable Information (PII) detection.
In the Azure AI Language service, PII detection is a built-in feature designed to automatically identify and redact sensitive or confidential information from text data. According to the Microsoft Learn module “Identify capabilities of Azure AI Language” and the AI-900 study guide, this capability can detect personal data such as names, phone numbers, email addresses, credit card numbers, and other identifiers.
When applied, the service scans input text and either masks or removes these PII elements based on configurable parameters, ensuring compliance with data privacy regulations like GDPR or HIPAA.
For example, if a document contains “John Doe’s phone number is 555-123-4567,” PII detection can return “******’s phone number is ***********,” thereby preventing exposure of sensitive personal details.
Option analysis:
A. Personally Identifiable Information (PII) detection: ✅ Correct. It identifies and masks sensitive data in text.
B. Entity linking: Connects recognized entities to known data sources like Wikipedia; not used for redaction.
C. Custom text classification: Classifies text into predefined categories; not designed for masking personal data.
D. Custom named entity recognition (NER): Detects domain-specific entities you define but doesn’t automatically mask them.
Therefore, to automate masking of names and phone numbers, the appropriate Azure AI Language feature is PII detection.
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:

Explanation:
facial analysis.
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe features of computer vision workloads on Azure,” facial analysis is a computer vision capability that detects faces and extracts attributes such as facial expressions, emotions, pose, occlusion, and image quality factors like exposure and noise. It does not identify or verify individual identities; rather, it interprets facial features and image characteristics to analyze conditions in an image.
In this question, the AI solution helps photographers take better portrait photos by providing feedback on exposure, noise, and occlusion — tasks directly linked to facial analysis. The model analyzes the detected face to determine if the image is well-lit, clear, and unobstructed, thereby improving photo quality. These capabilities are part of the Azure Face service in Azure Cognitive Services, which includes both facial detection and facial analysis functionalities.
Here’s how the other options differ:
Facial detection only identifies that a face exists in an image and provides its location using bounding boxes, without further interpretation.
Facial recognition goes a step further — it attempts to identify or verify a person’s identity by comparing the detected face with stored images. This is not what the scenario describes.
Thus, when an AI solution evaluates image quality aspects like exposure, noise, and occlusion, it’s performing facial analysis, which focuses on understanding image and facial characteristics rather than identification.
In summary, based on Microsoft’s AI-900 study material, this scenario demonstrates facial analysis, a subcategory of computer vision tasks within Azure Cognitive Services.
In which scenario should you use key phrase extraction?
Options:
translating a set of documents from English to German
generating captions for a video based on the audio track
identifying whether reviews of a restaurant are positive or negative
identifying which documents provide information about the same topics
Answer:
DExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Extract insights from text with the Text Analytics service”, key phrase extraction is a feature of the Text Analytics service that identifies the most important words or phrases in a given document. It helps summarize the main ideas by isolating significant concepts or terms that describe what the text is about.
In this scenario, the goal is to determine which documents share similar topics or themes. By extracting key phrases from each document (for example, “policy renewal,” “coverage limits,” “claim process”), you can compare and categorize documents based on overlapping keywords. This is exactly how key phrase extraction is used—to summarize and group text content by topic relevance.
The other options do not fit this use case:
A. Translation uses the Translator service, not key phrase extraction.
B. Generating video captions involves speech recognition and computer vision.
C. Identifying sentiment relates to sentiment analysis, not key phrase extraction.
You need to build an image tagging solution for social media that tags images of your friends automatically. Which Azure Cognitive Services service should you use?
Options:
Computer Vision
Face
Text Analytics
Form Recognizer
Answer:
BExplanation:
The correct answer is B. Face because the Azure Face service, part of Azure Cognitive Services, provides capabilities for detecting, recognizing, and analyzing human faces in images. According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Explore computer vision”, the Face service can automatically detect faces, determine attributes such as age, gender, emotion, and identify or verify individuals based on facial features.
In this scenario, the goal is to build an image tagging solution that automatically tags images of friends on social media. This requires the ability to recognize and match faces of known individuals, which is a key feature of the Face API. The API uses facial recognition technology to create face IDs for detected faces and can compare new faces against stored face data to identify known individuals. Microsoft Learn notes: “The Face service can detect, recognize, and identify people in images, enabling automated tagging or authentication scenarios.”
Other options explained:
A. Computer Vision identifies objects, landmarks, and general content but does not specialize in identifying individual people.
C. Text Analytics analyzes textual data for sentiment, key phrases, or entities, not image data.
D. Form Recognizer extracts structured data from forms or receipts, unrelated to face detection.
Thus, for automatically tagging people in photos, Azure Face is the correct and most suitable service.
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:

Explanation:
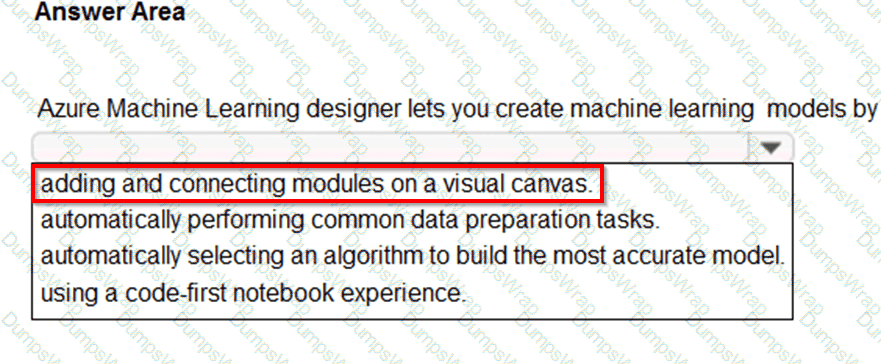
The correct answer is “adding and connecting modules on a visual canvas.”
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore automated machine learning in Azure Machine Learning,” the Azure Machine Learning designer is a drag-and-drop, no-code environment that allows users to create, train, and deploy machine learning models visually. It is specifically designed for users who prefer an intuitive graphical interface rather than writing extensive code.
Microsoft Learn defines Azure Machine Learning designer as a tool that allows you to “build, test, and deploy machine learning models by dragging and connecting pre-built modules on a visual canvas.” These modules can represent data inputs, transformations, training algorithms, and evaluation processes. By linking them together, users can create an end-to-end machine learning pipeline.
The designer simplifies the machine learning workflow by allowing data scientists, analysts, and even non-developers to:
Import and prepare datasets visually.
Choose and connect algorithm modules (e.g., classification, regression, clustering).
Train and evaluate models interactively.
Publish inference pipelines as web services for prediction.
Let’s analyze the other options:
Automatically performing common data preparation tasks – This describes Automated ML (AutoML), not the Designer.
Automatically selecting an algorithm to build the most accurate model – Also a characteristic of AutoML, where the system tests multiple algorithms automatically.
Using a code-first notebook experience – This describes the Azure Machine Learning notebooks environment, which uses Python and SDKs, not the Designer interface.
Therefore, based on the official AI-900 learning objectives and Microsoft Learn documentation, the Azure Machine Learning designer allows you to create models by adding and connecting modules on a visual canvas, providing a no-code, interactive experience ideal for users building custom machine learning workflows visually.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore fundamental principles of machine learning,” a regression model is used when the goal is to predict a continuous numerical value based on historical data.
In this question, the task is to predict the sale price of auctioned items, which is a numeric output that can take on a wide range of values (for example, $50.25, $199.99, etc.). This makes it a regression problem because the output is continuous rather than categorical.
Regression models analyze the relationship between input features (such as item type, condition, age, bidding history, or demand) and a numerical target variable (the sale price). Common regression algorithms include linear regression, decision tree regression, and neural network regression. In Azure Machine Learning, these models are trained using labeled datasets containing known outcomes to learn patterns and make future predictions.
Let’s review the incorrect options:
Classification: Used to predict discrete categories or labels, such as “sold” vs. “unsold” or “low,” “medium,” “high.” It cannot output continuous numeric predictions.
Clustering: An unsupervised technique used to group similar data points based on shared characteristics, not to predict specific numeric outcomes.
Therefore, because predicting a sale price involves forecasting a continuous numerical value, the correct model type is Regression.
This aligns with Microsoft’s AI-900 teaching that regression is used for tasks such as:
Predicting house prices
Forecasting sales revenue
Estimating car values or auction prices
Which type of machine learning should you use to identify groups of people who have similar purchasing habits?
Options:
classification
regression
clustering
Answer:
CExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Describe features of common AI workloads”, clustering is a type of unsupervised machine learning used to group data points that share similar characteristics. In unsupervised learning, the data provided to the model does not have predefined labels or outcomes. Instead, the algorithm identifies inherent patterns or groupings within the dataset based on similarities in input features.
In this scenario, the task is to identify groups of people who have similar purchasing habits. There is no predefined label such as “buyer type” or “purchase category.” The goal is to discover hidden patterns—such as grouping customers by spending behavior, preferred products, or frequency of purchases. This is precisely what clustering algorithms are designed to do.
Clustering is commonly used in:
Customer segmentation for marketing analytics.
Market basket analysis to find associations in purchasing patterns.
Recommender systems to identify similar user profiles.
Anomaly detection when outliers deviate from natural clusters.
Typical algorithms for clustering include K-means, Hierarchical clustering, and DBSCAN. These models analyze multidimensional data to form clusters that maximize intra-group similarity and minimize inter-group similarity.
By contrast:
Classification (A) is a supervised learning method that predicts a categorical label (e.g., whether a customer will churn or not). It requires labeled training data.
Regression (B) is used to predict continuous numeric values (e.g., sales revenue, temperature).
Since the question focuses on discovering groups of similar customers without prior labels, the correct type of machine learning is Clustering.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:
Statement
Yes / No
Providing an explanation of the outcome of a credit loan application is an example of the Microsoft transparency principle for responsible AI.
Yes
A triage bot that prioritizes insurance claims based on injuries is an example of the Microsoft reliability and safety principle for responsible AI.
Yes
An AI solution that is offered at different prices for different sales territories is an example of the Microsoft inclusiveness principle for responsible AI.
No
This question is based on the Responsible AI principles defined by Microsoft, a major topic in the AI-900: Microsoft Azure AI Fundamentals certification. The goal of Responsible AI is to ensure that artificial intelligence is developed and used ethically, safely, and transparently to benefit people and society. Microsoft’s framework defines six core principles: Fairness, Reliability and Safety, Privacy and Security, Inclusiveness, Transparency, and Accountability.
Transparency Principle – YesProviding an explanation for a loan application decision clearly reflects transparency. According to Microsoft’s Responsible AI guidelines, transparency involves ensuring that users and stakeholders understand how AI systems make decisions. When a financial AI model explains why a loan was approved or denied, it promotes user trust and confidence in automated decision-making. Transparency helps individuals understand influencing factors (like income or credit score), thereby fostering ethical AI deployment.
Reliability and Safety Principle – YesA triage bot that prioritizes insurance claims based on injury severity demonstrates reliability and safety. This principle ensures that AI systems consistently operate as intended, handle data accurately, and do not cause unintended harm. For a triage bot, safety means it must correctly interpret medical or claim information and consistently provide appropriate prioritization. Microsoft emphasizes that reliable AI systems must be tested rigorously, function correctly in various scenarios, and maintain user safety at all times.
Inclusiveness Principle – NoAn AI solution priced differently for various sales territories is unrelated to inclusiveness. Inclusiveness focuses on designing AI systems that are accessible and fair to all users, including those with disabilities or from different demographic backgrounds. Price variation across territories is a business strategy, not an ethical AI inclusion concern. Hence, this statement does not align with any Responsible AI principle.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and the Microsoft Learn module “Identify features of common machine learning types”, a regression model is a type of supervised machine learning model that is used to predict continuous numeric values based on one or more input variables (features).
In supervised learning, models are trained using labeled data, where each input record has a known target value (label). For regression specifically, the label represents a numeric quantity — such as price, age, temperature, or sales figures. The model learns to approximate a function that maps input variables to numeric outputs.
For example:
Predicting house prices based on size, location, and number of rooms.
Predicting monthly sales revenue from marketing spend and seasonality.
Forecasting temperature based on historical weather data.
In Azure Machine Learning Designer and AutoML, when building a regression model, the label column must therefore be of numeric data type (integer or float). If the label were categorical (for example, “yes/no” or “approved/denied”), the appropriate model type would be classification, not regression.
To contrast with other options:
Boolean – used in binary classification problems (true/false outcomes).
Datetime – used for time series forecasting, not standard regression labels.
Text – used as input features for NLP models, not as regression targets.
Hence, when configuring a regression task in Azure, ensuring the target variable (label) is numeric is a fundamental requirement. The model’s performance metrics—such as Mean Absolute Error (MAE), Root Mean Squared Error (RMSE), and R²—also rely on numeric computations.
You deploy the Azure OpenAI service to generate images.
You need to ensure that the service provides the highest level of protection against harmful content.
What should you do?
Options:
Configure the Content filters settings.
Customize a large language model (LLM).
Configure the system prompt
Change the model used by the Azure OpenAI service.
Answer:
AExplanation:
The correct answer is A. Configure the Content filters settings.
When using the Azure OpenAI Service for text or image generation, Microsoft provides built-in content filtering to help detect and block potentially harmful or unsafe outputs. These filters are part of Microsoft’s Responsible AI framework and are designed to prevent the generation of offensive, violent, sexual, or otherwise restricted content.
To ensure the highest level of protection, you can configure content filter settings within the Azure OpenAI deployment. This allows you to define stricter policies based on your organization’s safety requirements. For image generation models such as DALL·E, enabling or strengthening these filters ensures that inappropriate or unsafe images are not generated or returned.
B (Customize an LLM): Customization affects behavior but not safety filtering.
C (Configure the system prompt): Adjusts response style but doesn’t guarantee content safety.
D (Change the model): Different models have similar filter systems; protection level depends on filter configuration, not the model itself.
Match the computer vision service to the appropriate Al workload.
To answer, drag the appropriate service from the column on the left to its workload on the right. Each service may be used once, more than once, or not at all.
NOTE: Each correct match is worth one point.

Options:
Answer:

Explanation:

This question evaluates understanding of the different Azure AI Computer Vision services and their distinct functionalities, as covered in the Microsoft AI-900 study guide and Microsoft Learn modules under “Describe features of common AI workloads” and “Identify Azure services for computer vision.”
Azure AI Document Intelligence (formerly known as Form Recognizer):This service is designed to extract structured information from documents, such as forms, receipts, and invoices. It uses optical character recognition (OCR) combined with AI models to detect key-value pairs, tables, and handwritten text. This makes it ideal for automating data entry and digitizing scanned documents. Hence, it matches “Extract information from scanned forms and invoices.”
Azure AI Vision (formerly Computer Vision):This service provides image and video analysis capabilities. It can detect objects, people, text, and scenes; generate image captions; and extract descriptive tags. It also supports OCR for printed and handwritten text within images. Therefore, it matches “Analyze images and video, and extract descriptions, tags, objects, and text.”
Azure AI Custom Vision:Custom Vision allows you to train your own image classification and object detection models using your own labeled images. Unlike the general Vision service, Custom Vision lets you build domain-specific models—for example, detecting your company’s products or identifying manufacturing defects. Hence, it matches “Train custom image classification and object detection models by using your own images.”
These three services complement each other within Azure’s computer vision ecosystem, collectively supporting both general-purpose and specialized AI solutions for visual data analysis.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE; Each correct selection is worth one point.

Options:
Answer:

Explanation:
Yes, Yes, No.
According to the Microsoft Azure AI Fundamentals (AI-900) study materials, conversational AI enables applications, websites, and digital assistants to interact with users via natural language. A chatbot is a key conversational AI workload and can be integrated into multiple channels such as web pages, Microsoft Teams, Facebook Messenger, and Cortana using Azure Bot Service and Bot Framework.
“A restaurant can use a chatbot to answer queries through Cortana” — Yes.Azure Bot Service supports multi-channel deployment, which includes Cortana integration. This means the same bot can respond to voice or text input via Cortana, making it a valid use case for a restaurant to provide menu details, reservations, or order tracking through voice-based AI assistants.
“A restaurant can use a chatbot to answer inquiries about business hours from a webpage” — Yes.This is a standard scenario for chatbots embedded on a company website. As per Microsoft Learn’s Describe features of conversational AI module, a chatbot can be added to a website to handle FAQs such as business hours, location, or menu details, thereby improving response time and reducing repetitive human workload.
“A restaurant can use a chatbot to automate responses to customer reviews on an external website” — No.Azure bots and other conversational AI tools cannot automatically interact with or post on external third-party platforms where the business does not control the data or API integration. Automated posting or replying to reviews on external review sites (e.g., Yelp or Google Reviews) would violate both ethical and technical boundaries of responsible AI usage outlined by Microsoft.
Which two scenarios are examples of a conversational AI workload? Each correct answer presents a complete solution.
NOTE: Each correct selection is worth one point.
Options:
a telephone answering service that has a pre-recorder message
a chatbot that provides users with the ability to find answers on a website by themselves
telephone voice menus to reduce the load on human resources
a service that creates frequently asked questions (FAQ) documents by crawling public websites
Answer:
B, CExplanation:
According to the AI-900 official study guide and Microsoft Learn module “Describe features of conversational AI workloads on Azure”, conversational AI refers to artificial intelligence systems that interact with users through natural language via text or speech. These systems include chatbots, virtual assistants, and interactive voice response (IVR) systems that simulate human conversation.
B. Chatbot that provides users with the ability to find answers on a website by themselvesThis is a classic example of conversational AI. Chatbots use natural language understanding (LUIS) and Azure Bot Service to interpret user input, identify intent, and provide relevant responses automatically. They help users self-serve information without human support, such as retrieving account details or answering FAQs.
C. Telephone voice menus to reduce the load on human resourcesAutomated telephone systems or IVRs use conversational AI to interpret spoken commands and route calls intelligently. This is often implemented using Azure Cognitive Services Speech (for speech-to-text and text-to-speech) combined with Azure Bot Service for managing dialogue flow.
A smart device that responds to the question. " What is the stock price of Contoso, Ltd.? " is an example of which Al workload?
Options:
computer vision
anomaly detection
knowledge mining
natural language processing
Answer:
DExplanation:
The question describes a smart device that can understand and respond to a spoken or written question such as, “What is the stock price of Contoso, Ltd.?” This scenario directly maps to the Natural Language Processing (NLP) workload in Microsoft Azure AI.
According to the Microsoft AI Fundamentals (AI-900) study guide and the Microsoft Learn module “Describe features of common AI workloads,” NLP enables systems to understand, interpret, and generate human language. Azure AI Language and Azure Speech services are examples of NLP-based solutions.
In this case, the smart device performs several NLP tasks:
Speech recognition – converts spoken input into text.
Language understanding – interprets the user’s intent, i.e., retrieving the stock price of a specific company.
Response generation – formulates a meaningful answer that can be presented back as text or speech.
This process shows a full pipeline of natural language understanding (NLU) and conversational AI. It does not involve visual data (computer vision), data pattern analysis (anomaly detection), or document search (knowledge mining).
Hence, the correct AI workload is D. Natural Language Processing.
You have a custom question answering solution.
You create a bot that uses the knowledge base to respond to customer requests. You need to identify what the bot can perform without adding additional skills. What should you identify?
Options:
Register customer complaints.
Answer questions from multiple users simultaneously.
Register customer purchases.
Provide customers with return materials authorization (RMA) numbers.
Answer:
BExplanation:
According to the AI-900 Microsoft Learn modules on Conversational AI, a custom question answering solution built using Azure AI Language (formerly QnA Maker) enables a chatbot to respond to user questions based on a predefined knowledge base. When integrated with a bot, the solution can automatically respond to multiple user queries in real time without additional programming.
This capability is known as scalability and concurrency, which allows chatbots to manage simultaneous conversations with multiple users. This feature is built into the Azure Bot Service, meaning you don’t need to add extra “skills” or custom logic for concurrent interactions.
Other options require additional integration or logic:
Register customer complaints or purchases would require connecting the bot to a CRM or sales system.
Provide RMA numbers requires business process logic or database access.
Therefore, the out-of-the-box functionality of a custom question answering bot is the ability to answer questions from multiple users at once, which is supported natively by Azure Bot Service and the QnA knowledge base.
Which Azure Cognitive Services service can be used to identify documents that contain sensitive information?
Options:
Custom Vision
Conversational Language Understanding
Form Recognizer
Answer:
CExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and Microsoft Learn module “Identify features of common AI workloads,” the Azure Form Recognizer service is part of Azure Cognitive Services for Document Intelligence. It enables organizations to extract, analyze, and identify information from structured and unstructured documents, including sensitive or confidential data such as names, addresses, financial figures, and identification numbers.
Form Recognizer uses optical character recognition (OCR) combined with machine learning to automatically extract key-value pairs, tables, and text fields from documents like invoices, receipts, contracts, and forms. It can be customized to identify and classify documents that contain specific sensitive data, allowing businesses to automate compliance and data governance tasks.
By contrast:
A. Custom Vision is used for image classification and object detection — it analyzes visual data, not document content.
B. Conversational Language Understanding (formerly LUIS) identifies intent and entities in text conversations, not document structure or sensitive data.
Form Recognizer is explicitly mentioned in the AI-900 course as the tool for document analysis and extraction. It can even integrate with Azure Cognitive Search or Azure Purview for further data management and compliance workflows.
Therefore, the verified and correct answer, aligned with Microsoft’s official training content, is C. Form Recognizer, as it is the Azure Cognitive Service capable of identifying and processing documents containing sensitive information.
To complete the sentence, select the appropriate option in the answer area.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) study guide and official Microsoft Learn modules under “Describe features of common AI workloads”, Conversational AI refers to technology that enables computers to engage in dialogue or conversation with users through natural language, whether by text or speech. The interactive answering of user-entered questions through a chat interface or virtual assistant is a direct example of a conversational AI workload.
Microsoft defines Conversational AI as systems that use natural language processing (NLP) and language understanding models to interpret what users are asking and respond appropriately. This includes chatbots, virtual assistants (like Cortana or Azure Bot Service), and automated customer service systems that simulate a human-like conversation. In this case, when an application answers questions that a user types interactively, the AI model is processing human language inputs, deriving intent, and generating meaningful replies — precisely what conversational AI is designed to do.
By contrast:
Anomaly detection identifies unusual patterns in data, typically used for fraud detection or equipment monitoring — not interactive dialogue.
Computer vision deals with interpreting images or video (e.g., object detection, facial recognition), unrelated to answering text-based questions.
Forecasting uses historical data to predict future trends or outcomes, often in sales or demand prediction scenarios.
The AI-900 guide emphasizes that Conversational AI helps businesses improve customer interaction efficiency by offering instant, automated, and consistent responses. It enables real-time engagement 24/7 and integrates with tools such as Azure Bot Service, Azure Cognitive Service for Language, and QnA Maker (now part of Azure AI Language Service).
Therefore, based on the Microsoft Learn objectives and definitions from the official AI-900 curriculum, the interactive answering of user questions in an application is best categorized as Conversational AI.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

According to the Microsoft Azure AI Fundamentals (AI-900) official study materials and Microsoft Learn documentation on GitHub Copilot, the GitHub Copilot extension for Microsoft Visual Studio Code (VS Code) is powered by the OpenAI Codex model, a specialized descendant of the GPT (Generative Pre-trained Transformer) family of models. The OpenAI Codex model is specifically fine-tuned for programming tasks—it understands and generates code in multiple programming languages such as Python, JavaScript, C#, and more.
GitHub Copilot functions as an AI-powered coding assistant that suggests complete lines or blocks of code, helps write comments, and can even generate functions based on natural language prompts entered by the developer. When a user types a comment like “// sort a list of numbers in ascending order,” Copilot uses the Codex model to understand the intent and generate an appropriate code implementation.
The integration with Visual Studio Code allows developers to work efficiently without needing to switch between documentation and their coding environment. GitHub Copilot leverages context-aware suggestions, meaning it understands the surrounding code, function definitions, and variable names to provide relevant completions.
The other options are incorrect because:
GitHub source control manages code repositories but doesn’t use AI models.
IntelliSense is a built-in VS Code feature for code completion but doesn’t rely on OpenAI models.
Microsoft 365 Copilot uses large language models (like GPT-4) for productivity tools such as Word, Excel, and Outlook—not for code generation.
Therefore, the correct choice that uses the OpenAI Codex model in Visual Studio Code is GitHub Copilot, aligning with Microsoft’s AI-900 learning objectives under “Identify common use cases for Azure OpenAI and GitHub Copilot.”
You are creating an app to help employees write emails and reports based on user prompts. What should you use?
Options:
Azure Al Speech
Azure OpenAI in Foundry Models
Azure Al Vision
Azure Machine Learning studio
Answer:
BExplanation:
For an app that helps employees write emails and reports based on user prompts, you need a text generation model capable of understanding natural language instructions and producing coherent, contextually appropriate output. Azure OpenAI GPT models—available through Azure AI Foundry (formerly Azure OpenAI Studio)—are specifically designed for such generative tasks.
By integrating GPT-3.5 or GPT-4, the app can analyze prompts like “Write a professional email to a client about project updates” and automatically generate polished text in seconds.
The other options do not fit:
A. Azure AI Speech: Converts spoken language to text or text to speech; not suitable for generating written content.
C. Azure AI Vision: Processes and analyzes images or video content.
D. Azure Machine Learning Studio: Used for training, testing, and deploying custom ML models, not directly for content generation.
Therefore, to create a writing-assistance app for emails and reports, the correct solution is B. Azure OpenAI in Foundry Models using GPT-based language generation.
Which parameter should you configure to produce a more diverse range of tokens in the responses from a chat solution that uses the Azure OpenAI GPT-3.5 model?
Options:
Max response
Past messages included
Presence penalty
Stop sequence
Answer:
CExplanation:
In Azure OpenAI Service, model behavior during text or chat generation is controlled by several parameters, such as temperature, max tokens, top_p, presence penalty, and frequency penalty. According to Microsoft Learn’s documentation for Azure OpenAI GPT models, the presence penalty influences how likely the model is to introduce new or diverse tokens in its responses.
Specifically, the presence penalty discourages the model from repeating previously used tokens, encouraging it to explore new topics or ideas instead of sticking to existing ones. Increasing the presence penalty value typically results in more diverse and creative outputs, while lowering it makes responses more repetitive or focused.
Option analysis:
A. Max response (Max tokens): Controls the maximum length of the generated response, not its diversity.
B. Past messages included: Defines how much chat history the model considers for context; it doesn’t affect diversity directly.
C. Presence penalty: Encourages novelty and introduces new tokens—this is correct for increasing response variety.
D. Stop sequence: Specifies a sequence of characters or tokens where the model should stop generating output.
Which Azure service can use the prebuilt receipt model in Azure Al Document Intelligence?
Options:
Azure Al Computer Vision
Azure Machine Learning
Azure Al Services
Azure Al Custom Vision
Answer:
CExplanation:
The prebuilt receipt model is part of Azure AI Document Intelligence (formerly Form Recognizer), which belongs to the broader Azure AI Services family. The prebuilt receipt model is designed to automatically extract key information such as merchant names, dates, totals, and tax amounts from receipts without requiring custom training.
Among the given options, C. Azure AI Services is correct because it encompasses all cognitive AI capabilities—vision, language, speech, and document processing. Specifically, Azure AI Document Intelligence is included within Azure AI Services and provides both prebuilt and custom models for processing invoices, receipts, business cards, and identity documents.
Options A (Computer Vision) and D (Custom Vision) are image-based services, not form-processing tools. Option B (Azure Machine Learning) focuses on building custom predictive models, not using prebuilt document models.
Therefore, the correct answer is C. Azure AI Services, which includes the prebuilt receipt model in Document Intelligence.
You are building a knowledge base by using QnA Maker. Which file format can you use to populate the knowledge base?
Options:
PPTX
XML
ZIP
Answer:
AExplanation:
QnA Maker supports automatic extraction of question-and-answer pairs from structured files such as PDF, Microsoft Word, or Excel documents, as well as from public webpages. This makes PDF the correct file format for populating a knowledge base.
Other options are invalid:
B. PPTX – Not supported.
C. XML – Not a recognized input for QnA Maker.
D. ZIP – Used for packaging, not Q & A content.
You have the following dataset.

You plan to use the dataset to train a model that will predict the house price categories of houses.
What are Household Income and House Price Category? To answer, select the appropriate option in the answer area.
NOTE: Each correct selection is worth one point.

Options:
Answer:
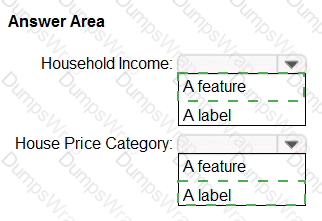
Explanation:
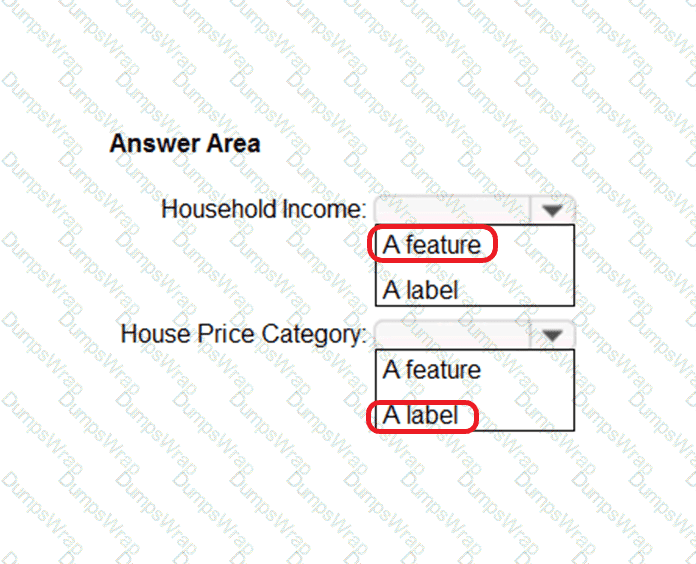
In machine learning, especially within the Microsoft Azure AI Fundamentals (AI-900) framework, datasets used for supervised learning are composed of features (inputs) and labels (outputs). According to the Microsoft Learn module “Explore the machine learning process”, a feature is any measurable property or attribute used by the model to make predictions, whereas a label is the actual value or category the model is trying to predict.
Household Income → FeatureA feature (also known as an independent variable) represents the input data that the machine learning algorithm uses to detect patterns or correlations. In this dataset, Household Income is a numeric value that influences the prediction of house price categories. During training, the model learns how variations in household income correlate with changes in the house price category. Microsoft Learn defines features as “the attributes or measurable inputs that are used to train the model.” Thus, Household Income serves as a predictive input or feature.
House Price Category → LabelThe label (or dependent variable) represents the output the model aims to predict. It is the known result during training that helps the algorithm learn correct mappings between features and outcomes. In this scenario, House Price Category—which can take values such as “Low,” “Middle,” or “High”—is the classification outcome that the model will predict based on household income (and possibly other variables). According to Microsoft Learn, “the label is the variable that contains the known values that the model is trained to predict.”
In summary, the dataset defines a supervised learning classification problem, where Household Income is the feature (input) and House Price Category is the label (output) that the model will learn to predict.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

This question evaluates understanding of fundamental machine learning concepts as covered in the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Explore the machine learning process.” These statements relate to data labeling, model evaluation practices, and performance metrics—three essential parts of building and assessing a machine learning model.
Labelling is the process of tagging training data with known values → YesAccording to Microsoft Learn, “Labeling is the process of tagging data with the correct output value so the model can learn relationships between inputs and outputs.” This is essential for supervised learning, where models require historical data with known outcomes. For example, if training a model to recognize fruit images, each image is labeled as “apple,” “banana,” or “orange.” Hence, this statement is true.
You should evaluate a model by using the same data used to train the model → NoThe AI-900 guide stresses that using the same data for both training and evaluation can cause overfitting, where the model performs well on training data but poorly on unseen data. Instead, the dataset is split into training and testing (or validation) subsets. Evaluation must use test data that the model has never seen before to ensure an unbiased measure of performance. Therefore, this statement is false.
Accuracy is always the primary metric used to measure a model’s performance → NoMicrosoft Learn emphasizes that accuracy is only one metric and not always the best choice. Depending on the problem type, other metrics such as precision, recall, F1-score, or AUC (Area Under the Curve) may be more appropriate—especially in cases with imbalanced datasets. For example, in fraud detection, recall may be more important than accuracy. Thus, this statement is false.
For each of the following statements, select Yes if the statement is true. Otherwise, select No.
NOTE: Each correct selection is worth one point.

Options:
Answer:

Explanation:

This question evaluates understanding of clustering—an unsupervised learning technique explained in the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Explore fundamental principles of machine learning.” Clustering involves finding natural groupings within data without prior knowledge of output labels. The algorithm identifies similarities among data points and groups them accordingly, with each group (or cluster) containing items that are more similar to each other than to those in other groups.
Organizing documents into groups based on similarities of the text contained in the documents → YesThis is a classic clustering application. In text analytics or natural language processing (NLP), clustering algorithms such as K-means or hierarchical clustering are used to group documents with similar content or topics. According to Microsoft Learn, “clustering identifies relationships in data and groups items that share common characteristics.” Therefore, organizing text documents based on content similarity is a textbook example of clustering.
Grouping similar patients based on symptoms and diagnostic test results → YesThis is another example of clustering. In healthcare analytics, clustering can be used to segment patients with similar health patterns or risks. The study guide emphasizes that clustering can “discover natural groupings in data such as customers with similar buying patterns or patients with similar clinical results.” Thus, this task correctly describes unsupervised clustering because it does not involve predicting a known outcome but grouping based on similarity.
Predicting whether a person will develop mild, moderate, or severe allergy symptoms based on pollen count → NoThis is a classification problem, not clustering. Classification is a supervised learning technique where the model is trained with labeled data to predict predefined categories (in this case, mild, moderate, or severe). Microsoft Learn clearly distinguishes between clustering (discovering hidden patterns) and classification (predicting predefined categories).
You need to identify harmful content in a generative Al solution that uses Azure OpenAI Service.
What should you use?
Options:
Face
Video Analysis
Language
Content Safety
Answer:
DExplanation:
According to the Microsoft Azure AI Fundamentals (AI-900) curriculum and Azure OpenAI documentation, the appropriate service for detecting and managing harmful, unsafe, or inappropriate content in text, images, or other generative AI outputs is Azure AI Content Safety.
Azure AI Content Safety is designed to automatically detect potentially harmful material such as hate speech, violence, self-harm, sexual content, or profanity. It ensures that generative AI applications like chatbots, image generators, and content creation tools comply with Microsoft’s Responsible AI principles — specifically Reliability & Safety and Accountability.
This service integrates directly with the Azure OpenAI Service, meaning that when developers build AI solutions using models like GPT-4 or DALL·E, they can use Content Safety to filter and moderate both input prompts and model outputs. This protects users from unsafe or offensive content generation.
Let’s analyze why the other options are incorrect:
A. Face – The Face service detects and analyzes human faces in images or videos. It is unrelated to moderating harmful textual or generative content.
B. Video Analysis – This service analyzes video streams to detect objects, actions, or events but not inappropriate or harmful text or imagery from AI models.
C. Language – The Azure AI Language service focuses on text understanding tasks like sentiment analysis, entity recognition, and translation, not content safety filtering.
Therefore, per Microsoft Learn’s official AI-900 guidance, when identifying or filtering harmful content in a generative AI solution built with Azure OpenAI, the correct and verified service to use is Azure AI Content Safety.
Match the types of AI workloads to the appropriate scenarios.
To answer, drag the appropriate workload type from the column on the left to its scenario on the right. Each workload type may be used once, more than once, or not at all.
NOTE: Each correct selection is worth one point.
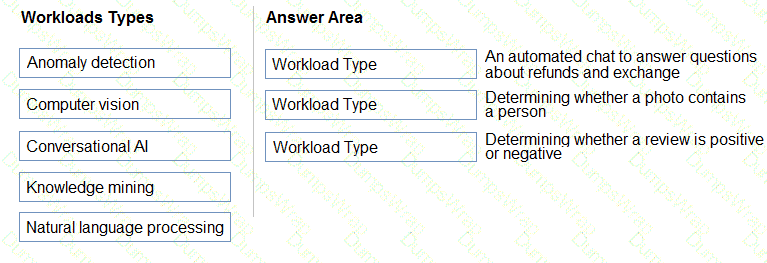
Options:
Answer:

Explanation:

Box 3: Natural language processing
Natural language processing (NLP) is used for tasks such as sentiment analysis, topic detection, language detection, key phrase extraction, and document categorization.
To complete the sentence, select the appropriate option in the answer area.
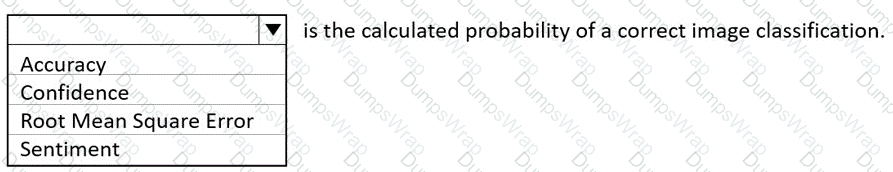
Options:
Answer:

Explanation:
Confidence.
According to the Microsoft Azure AI Fundamentals (AI-900) Official Study Guide and the Microsoft Learn module “Explore computer vision in Microsoft Azure,” the confidence score represents the calculated probability that a model’s prediction is correct. In image classification, when an AI model analyzes an image and assigns it to a specific category, it also produces a confidence value—a numerical probability (usually between 0 and 1) indicating how certain the model is about its prediction.
For example, if an image classification model identifies an image as a “cat” with a confidence of 0.92, it means the model is 92% certain that the image depicts a cat. The confidence value helps developers and users understand the model’s certainty level about its classification output.
Microsoft Learn emphasizes that in Azure Cognitive Services—such as the Custom Vision Service—each prediction result includes both the predicted label (class) and a confidence score. These confidence scores are essential for evaluating model performance and determining thresholds for automated decisions (e.g., accepting predictions only above a 0.8 probability).
Let’s evaluate the other options:
Accuracy: This is an overall performance metric measuring the percentage of correct predictions across the dataset, not a probability for a single prediction.
Root Mean Square Error (RMSE): This is a metric for regression models, not classification tasks. It measures average error magnitude between predicted and actual values.
Sentiment: This is a type of prediction (positive, negative, neutral) in text analysis, not a probability metric.
Therefore, based on Microsoft’s AI-900 training materials and Azure Cognitive Services documentation, the calculated probability of a correct image classification is called Confidence, which expresses how sure the model is about its prediction for a specific input.
You are authoring a Language Understanding (LUIS) application to support a music festival.
You want users to be able to ask questions about scheduled shows, such as: “Which act is playing on the main stage?”
The question “Which act is playing on the main stage?” is an example of which type of element?
Options:
an intent
an utterance
a domain
an entity
Answer:
BExplanation:
In a Language Understanding (LUIS) application, an utterance represents an example of what a user might say to the bot. According to Microsoft Learn – “Build a Language Understanding app”, an utterance is a sample phrase that helps train the LUIS model to recognize user intent.
In the given example — “Which act is playing on the main stage?” — the statement is an utterance that a user might say to find out about show schedules. LUIS uses utterances like this to identify the intent (the user’s goal, e.g., GetShowInfo) and to extract any entities (e.g., main stage) that provide additional details for fulfilling the request.
To clarify the other elements:
Intent: The overall purpose or action (e.g., “FindShowDetails”).
Entity: Specific information in the utterance (e.g., “main stage”).
Domain: A general subject area (e.g., entertainment, events).
Thus, “Which act is playing on the main stage?” is an utterance used to train the LUIS model to understand natural language input.
Select the answer that correctly completes the sentence.

Options:
Answer:

Explanation:

The correct completion of the sentence “_____ is an example of speech recognition.” is A voice-activated security key system.
According to the Microsoft Azure AI Fundamentals (AI-900) official study guide and Microsoft Learn module “Describe features of common AI workloads”, speech recognition refers to the ability of a system or application to convert spoken language into text or actionable commands. It allows computers to interpret and respond to human speech inputs, bridging human-computer interaction through natural language.
Microsoft Learn clearly explains that speech recognition is used in applications such as voice assistants, dictation software, and voice-activated security systems, where the spoken input from a user is captured, analyzed, and translated into commands or text. For example, when a user says “Unlock door” or “Open session,” the speech recognition system interprets that sound input, converts it into text or a command, and then performs the appropriate action. This is a direct implementation of speech-to-text processing combined with command execution logic.
Let’s analyze the other options:
Creating an audio commentary for a video recording is related to speech synthesis (text-to-speech), not recognition.
Creating captions for a video recording involves speech-to-text transcription, which is a subset of speech recognition, but the question emphasizes a system that responds to voice commands, making the first option more accurate.
Identifying key phrases in a video transcript involves natural language processing (NLP) techniques rather than speech recognition.
Therefore, the voice-activated security key system best represents the use of speech recognition technology because it interprets spoken commands and takes a corresponding action based on recognized speech patterns. This aligns directly with the AI-900 learning objectives where speech recognition is defined as a process that enables applications to interpret and respond to human voice input.
