Splunk Enterprise Certified Architect Questions and Answers
Which Splunk Enterprise offering has its own license?
Options:
Splunk Cloud Forwarder
Splunk Heavy Forwarder
Splunk Universal Forwarder
Splunk Forwarder Management
Answer:
CExplanation:
The Splunk Universal Forwarder is the only Splunk Enterprise offering that has its own license. The Splunk Universal Forwarder license allows the forwarder to send data to any Splunk Enterprise or Splunk Cloud instance without consuming any license quota. The Splunk Heavy Forwarder does not have its own license, but rather consumes the license quota of the Splunk Enterprise or Splunk Cloud instance that it sends data to. The Splunk Cloud Forwarder and the Splunk Forwarder Management are not separate Splunk Enterprise offerings, but rather features of the Splunk Cloud service. For more information, see [About forwarder licensing] in the Splunk documentation.
A Splunk environment collecting 10 TB of data per day has 50 indexers and 5 search heads. A single-site indexer cluster will be implemented. Which of the following is a best practice for added data resiliency?
Options:
Set the Replication Factor to 49.
Set the Replication Factor based on allowed indexer failure.
Always use the default Replication Factor of 3.
Set the Replication Factor based on allowed search head failure.
Answer:
BExplanation:
The correct answer is B. Set the Replication Factor based on allowed indexer failure. This is a best practice for adding data resiliency to a single-site indexer cluster, as it ensures that there are enough copies of each bucket to survive the loss of one or more indexers without affecting the searchability of the data1. The Replication Factor is the number of copies of each bucket that the cluster maintains across the set of peer nodes2. The Replication Factor should be set according to the number of indexers that can fail without compromising the cluster’s ability to serve data1. For example, if the cluster can tolerate the loss of two indexers, the Replication Factor should be set to three1.
The other options are not best practices for adding data resiliency. Option A, setting the Replication Factor to 49, is not recommended, as it would create too many copies of each bucket and consume excessive disk space and network bandwidth1. Option C, always using the default Replication Factor of 3, is not optimal, as it may not match the customer’s requirements and expectations for data availability and performance1. Option D, setting the Replication Factor based on allowed search head failure, is not relevant, as the Replication Factor does not affect the search head availability, but the searchability of the data on the indexers1. Therefore, option B is the correct answer, and options A, C, and D are incorrect.
1: Configure the replication factor 2: About indexer clusters and index replication
Data for which of the following indexes will count against an ingest-based license?
Options:
summary
main
_metrics
_introspection
Answer:
BExplanation:
Splunk Enterprise licensing is based on the amount of data that is ingested and indexed by the Splunk platform per day1. The data that counts against the license is the data that is stored in the indexes that are visible to the users and searchable by the Splunk software2. The indexes that are visible and searchable by default are the main index and any custom indexes that are created by the users or the apps3. The main index is the default index where Splunk Enterprise stores all data, unless otherwise specified4.
Option B is the correct answer because the data for the main index will count against the ingest-based license, as it is a visible and searchable index by default. Option A is incorrect because the summary index is a special type of index that stores the results of scheduled reports or accelerated data models, which do not count against the license. Option C is incorrect because the _metrics index is an internal index that stores metrics data about the Splunk platform performance, which does not count against the license. Option D is incorrect because the _introspection index is another internal index that stores data about the impact of the Splunk software on the host system, such as CPU, memory, disk, and network usage, which does not count against the license.
References:
1: How Splunk Enterprise licensing works - Splunk Documentation 2: What data counts against my license? - Splunk Documentation 3: [About indexes and indexers - Splunk Documentation] 4: [The main index - Splunk Documentation] : [Summary indexing - Splunk Documentation] : [About metrics indexes - Splunk Documentation] : [About the Monitoring Console - Splunk Documentation]
Which of the following would be the least helpful in troubleshooting contents of Splunk configuration files?
Options:
crash logs
search.log
btool output
diagnostic logs
Answer:
AExplanation:
Splunk configuration files are files that contain settings that control various aspects of Splunk behavior, such as data inputs, outputs, indexing, searching, clustering, and so on1. Troubleshooting Splunk configuration files involves identifying and resolving issues that affect the functionality or performance of Splunk due to incorrect or conflicting configuration settings. Some of the tools and methods that can help with troubleshooting Splunk configuration files are:
- search.log: This is a file that contains detailed information about the execution of a search, such as the search pipeline, the search commands, the search results, the search errors, and the search performance2. This file can help troubleshoot issues related to search configuration, such as props.conf, transforms.conf, macros.conf, and so on3.
- btool output: This is a command-line tool that displays the effective configuration settings for a given Splunk component, such as inputs, outputs, indexes, props, and so on4. This tool can help troubleshoot issues related to configuration precedence, inheritance, and merging, as well as identify the source of a configuration setting5.
- diagnostic logs: These are files that contain information about the Splunk system, such as the Splunk version, the operating system, the hardware, the license, the indexes, the apps, the users, the roles, the permissions, the configuration files, the log files, and the metrics6. These files can help troubleshoot issues related to Splunk installation, deployment, performance, and health7.
Option A is the correct answer because crash logs are the least helpful in troubleshooting Splunk configuration files. Crash logs are files that contain information about the Splunk process when it crashes, such as the stack trace, the memory dump, and the environment variables8. These files can help troubleshoot issues related to Splunk stability, reliability, and security, but not necessarily related to Splunk configuration9.
References:
1: About configuration files - Splunk Documentation 2: Use the search.log file - Splunk Documentation 3: Troubleshoot search-time field extraction - Splunk Documentation 4: Use btool to troubleshoot configurations - Splunk Documentation 5: Troubleshoot configuration issues - Splunk Documentation 6: About the diagnostic utility - Splunk Documentation 7: Use the diagnostic utility - Splunk Documentation 8: About crash logs - Splunk Documentation 9: [Troubleshoot Splunk Enterprise crashes - Splunk Documentation]
Which Splunk internal field can confirm duplicate event issues from failed file monitoring?
Options:
_time
_indextime
_index_latest
latest
Answer:
BExplanation:
According to the Splunk documentation1, the _indextime field is the time when Splunk indexed the event. This field can be used to confirm duplicate event issues from failed file monitoring, as it can show you when each duplicate event was indexed and if they have different _indextime values. You can use the Search Job Inspector to inspect the search job that returns the duplicate events and check the _indextime field for each event2. The other options are false because:
- The _time field is the time extracted from the event data, not the time when Splunk indexed the event. This field may not reflect the actual indexing time, especially if the event data has a different time zone or format than the Splunk server1.
- The _index_latest field is not a valid Splunk internal field, as it does not exist in the Splunk documentation or the Splunk data model3.
- The latest field is a field that represents the latest time bound of a search, not the time when Splunk indexed the event. This field is used to specify the time range of a search, along with the earliest field4.
If there is a deployment server with many clients and one deployment client is not updating apps, which of the following should be done first?
Options:
Choose a longer phone home interval for all of the deployment clients.
Increase the number of CPU cores for the deployment server.
Choose a corrective action based on the splunkd. log of the deployment client.
Increase the amount of memory for the deployment server.
Answer:
CExplanation:
The correct action to take first if a deployment client is not updating apps is to choose a corrective action based on the splunkd.log of the deployment client. This log file contains information about the communication between the deployment server and the deployment client, and it can help identify the root cause of the problem1. The other actions may or may not help, depending on the situation, but they are not the first steps to take. Choosing a longer phone home interval may reduce the load on the deployment server, but it will also delay the updates for the deployment clients2. Increasing the number of CPU cores or the amount of memory for the deployment server may improve its performance, but it will not fix the issue if the problem is on the deployment client side3. Therefore, option C is the correct answer, and options A, B, and D are incorrect.
1: Troubleshoot deployment server issues 2: Configure deployment clients 3: Hardware and software requirements for the deployment server
A customer is migrating 500 Universal Forwarders from an old deployment server to a new deployment server, with a different DNS name. The new deployment server is configured and running.
The old deployment server deployed an app containing an updated deploymentclient.conf file to all forwarders, pointing them to the new deployment server. The app was successfully deployed to all 500 forwarders.
Why would all of the forwarders still be phoning home to the old deployment server?
Options:
There is a version mismatch between the forwarders and the new deployment server.
The new deployment server is not accepting connections from the forwarders.
The forwarders are configured to use the old deployment server in $SPLUNK_HOME/etc/system/local.
The pass4SymmKey is the same on the new deployment server and the forwarders.
Answer:
CExplanation:
All of the forwarders would still be phoning home to the old deployment server, because the forwarders are configured to use the old deployment server in $SPLUNK_HOME/etc/system/local. This is the local configuration directory that contains the settings that override the default settings in $SPLUNK_HOME/etc/system/default. The deploymentclient.conf file in the local directory specifies the targetUri of the deployment server that the forwarder contacts for configuration updates and apps. If the forwarders have the old deployment server’s targetUri in the local directory, they will ignore the updated deploymentclient.conf file that was deployed by the old deployment server, because the local settings have higher precedence than the deployed settings. To fix this issue, the forwarders should either remove the deploymentclient.conf file from the local directory, or update it with the new deployment server’s targetUri. Option C is the correct answer. Option A is incorrect because a version mismatch between the forwarders and the new deployment server would not prevent the forwarders from phoning home to the new deployment server, as long as they are compatible versions. Option B is incorrect because the new deployment server is configured and running, and there is no indication that it is not accepting connections from the forwarders. Option D is incorrect because the pass4SymmKey is the shared secret key that the deployment server and the forwarders use to authenticate each other. It does not affect the forwarders’ ability to phone home to the new deployment server, as long as it is the same on both sides12
1: 2:
Users are asking the Splunk administrator to thaw recently-frozen buckets very frequently. What could the Splunk administrator do to reduce the need to thaw buckets?
Options:
Change f rozenTimePeriodlnSecs to a larger value.
Change maxTotalDataSizeMB to a smaller value.
Change maxHotSpanSecs to a larger value.
Change coldToFrozenDir to a different location.
Answer:
AExplanation:
The correct answer is A. Change frozenTimePeriodInSecs to a larger value. This is a possible solution to reduce the need to thaw buckets, as it increases the time period before a bucket is frozen and removed from the index1. The frozenTimePeriodInSecs attribute specifies the maximum age, in seconds, of the data that the index can contain1. By setting it to a larger value, the Splunk administrator can keep the data in the index for a longer time, and avoid having to thaw the buckets frequently. The other options are not effective solutions to reduce the need to thaw buckets. Option B, changing maxTotalDataSizeMB to a smaller value, would actually increase the need to thaw buckets, as it decreases the maximum size, in megabytes, of an index2. This means that the index would reach its size limit faster, and more buckets would be frozen and removed. Option C, changing maxHotSpanSecs to a larger value, would not affect the need to thaw buckets, as it only changes the maximum lifetime, in seconds, of a hot bucket3. This means that the hot bucket would stay hot for a longer time, but it would not prevent the bucket from being frozen eventually. Option D, changing coldToFrozenDir to a different location, would not reduce the need to thaw buckets, as it only changes the destination directory for the frozen buckets4. This means that the buckets would still be frozen and removed from the index, but they would be stored in a different location. Therefore, option A is the correct answer, and options B, C, and D are incorrect.
1: Set a retirement and archiving policy 2: Configure index size 3: Bucket rotation and retention 4: Archive indexed data
Which of the following should be done when installing Enterprise Security on a Search Head Cluster? (Select all that apply.)
Options:
Install Enterprise Security on the deployer.
Install Enterprise Security on a staging instance.
Copy the Enterprise Security configurations to the deployer.
Use the deployer to deploy Enterprise Security to the cluster members.
Answer:
A, DExplanation:
When installing Enterprise Security on a Search Head Cluster (SHC), the following steps should be done: Install Enterprise Security on the deployer, and use the deployer to deploy Enterprise Security to the cluster members. Enterprise Security is a premium app that provides security analytics and monitoring capabilities for Splunk. Enterprise Security can be installed on a SHC by using the deployer, which is a standalone instance that distributes apps and other configurations to the SHC members. Enterprise Security should be installed on the deployer first, and then deployed to the cluster members using the splunk apply shcluster-bundle command. Enterprise Security should not be installed on a staging instance, because a staging instance is not part of the SHC deployment process. Enterprise Security configurations should not be copied to the deployer, because they are already included in the Enterprise Security app package.
Which of the following is a valid use case that a search head cluster addresses?
Options:
Provide redundancy in the event a search peer fails.
Search affinity.
Knowledge Object replication.
Increased Search Factor (SF).
Answer:
CExplanation:
The correct answer is C. Knowledge Object replication. This is a valid use case that a search head cluster addresses, as it ensures that all the search heads in the cluster have the same set of knowledge objects, such as saved searches, dashboards, reports, and alerts1. The search head cluster replicates the knowledge objects across the cluster members, and synchronizes any changes or updates1. This provides a consistent user experience and avoids data inconsistency or duplication1. The other options are not valid use cases that a search head cluster addresses. Option A, providing redundancy in the event a search peer fails, is not a use case for a search head cluster, but for an indexer cluster, which maintains multiple copies of the indexed data and can recover from indexer failures2. Option B, search affinity, is not a use case for a search head cluster, but for a multisite indexer cluster, which allows the search heads to preferentially search the data on the local site, rather than on a remote site3. Option D, increased Search Factor (SF), is not a use case for a search head cluster, but for an indexer cluster, which determines how many searchable copies of each bucket are maintained across the indexers4. Therefore, option C is the correct answer, and options A, B, and D are incorrect.
1: About search head clusters 2: About indexer clusters and index replication 3: Configure search affinity 4: Configure the search factor
Which of the following are true statements about Splunk indexer clustering?
Options:
All peer nodes must run exactly the same Splunk version.
The master node must run the same or a later Splunk version than search heads.
The peer nodes must run the same or a later Splunk version than the master node.
The search head must run the same or a later Splunk version than the peer nodes.
Answer:
A, DExplanation:
The following statements are true about Splunk indexer clustering:
- All peer nodes must run exactly the same Splunk version. This is a requirement for indexer clustering, as different Splunk versions may have different data formats or features that are incompatible with each other. All peer nodes must run the same Splunk version as the master node and the search heads that connect to the cluster.
- The search head must run the same or a later Splunk version than the peer nodes. This is a recommendation for indexer clustering, as a newer Splunk version may have new features or bug fixes that improve the search functionality or performance. The search head should not run an older Splunk version than the peer nodes, as this may cause search errors or failures. The following statements are false about Splunk indexer clustering:
- The master node must run the same or a later Splunk version than the search heads. This is not a requirement or a recommendation for indexer clustering, as the master node does not participate in the search process. The master node should run the same Splunk version as the peer nodes, as this ensures the cluster compatibility and functionality.
- The peer nodes must run the same or a later Splunk version than the master node. This is not a requirement or a recommendation for indexer clustering, as the peer nodes do not coordinate the cluster activities. The peer nodes should run the same Splunk version as the master node, as this ensures the cluster compatibility and functionality. For more information, see [About indexer clusters and index replication] and [Upgrade an indexer cluster] in the Splunk documentation.
Which of the following is an indexer clustering requirement?
Options:
Must use shared storage.
Must reside on a dedicated rack.
Must have at least three members.
Must share the same license pool.
Answer:
DExplanation:
An indexer clustering requirement is that the cluster members must share the same license pool and license master. A license pool is a group of licenses that are assigned to a set of Splunk instances. A license master is a Splunk instance that manages the distribution and enforcement of licenses in a pool. In an indexer cluster, all cluster members must belong to the same license pool and report to the same license master, to ensure that the cluster does not exceed the license limit and that the license violations are handled consistently. An indexer cluster does not require shared storage, because each cluster member has its own local storage for the index data. An indexer cluster does not have to reside on a dedicated rack, because the cluster members can be located on different physical or virtual machines, as long as they can communicate with each other. An indexer cluster does not have to have at least three members, because a cluster can have as few as two members, although this is not recommended for high availability
When should multiple search pipelines be enabled?
Options:
Only if disk IOPS is at 800 or better.
Only if there are fewer than twelve concurrent users.
Only if running Splunk Enterprise version 6.6 or later.
Only if CPU and memory resources are significantly under-utilized.
Answer:
DExplanation:
Multiple search pipelines should be enabled only if CPU and memory resources are significantly under-utilized. Search pipelines are the processes that execute search commands and return results. Multiple search pipelines can improve the search performance by running concurrent searches in parallel. However, multiple search pipelines also consume more CPU and memory resources, which can affect the overall system performance. Therefore, multiple search pipelines should be enabled only if there are enough CPU and memory resources available, and if the system is not bottlenecked by disk I/O or network bandwidth. The number of concurrent users, the disk IOPS, and the Splunk Enterprise version are not relevant factors for enabling multiple search pipelines
An index has large text log entries with many unique terms in the raw data. Other than the raw data, which index components will take the most space?
Options:
Index files (*. tsidx files).
Bloom filters (bloomfilter files).
Index source metadata (sources.data files).
Index sourcetype metadata (SourceTypes. data files).
Answer:
AExplanation:
Index files (. tsidx files) are the main components of an index that store the raw data and the inverted index of terms. They take the most space in an index, especially if the raw data has many unique terms that increase the size of the inverted index. Bloom filters, source metadata, and sourcetype metadata are much smaller in comparison and do not depend on the number of unique terms in the raw data.
References:
- How the indexer stores indexes
- Splunk Enterprise Certified Architect Study Guide, page 17
In which phase of the Splunk Enterprise data pipeline are indexed extraction configurations processed?
Options:
Input
Search
Parsing
Indexing
Answer:
DExplanation:
Indexed extraction configurations are processed in the indexing phase of the Splunk Enterprise data pipeline. The data pipeline is the process that Splunk uses to ingest, parse, index, and search data. Indexed extraction configurations are settings that determine how Splunk extracts fields from data at index time, rather than at search time. Indexed extraction can improve search performance, but it also increases the size of the index. Indexed extraction configurations are applied in the indexing phase, which is the phase where Splunk writes the data and the .tsidx files to the index. The input phase is the phase where Splunk receives data from various sources and formats. The parsing phase is the phase where Splunk breaks the data into events, timestamps, and hosts. The search phase is the phase where Splunk executes search commands and returns results.
Which of the following items are important sizing parameters when architecting a Splunk environment? (select all that apply)
Options:
Number of concurrent users.
Volume of incoming data.
Existence of premium apps.
Number of indexes.
Answer:
A, B, CExplanation:
- Number of concurrent users: This is an important factor because it affects the search performance and resource utilization of the Splunk environment. More users mean more concurrent searches, which require more CPU, memory, and disk I/O. The number of concurrent users also determines the search head capacity and the search head clustering configuration12
- Volume of incoming data: This is another crucial factor because it affects the indexing performance and storage requirements of the Splunk environment. More data means more indexing throughput, which requires more CPU, memory, and disk I/O. The volume of incoming data also determines the indexer capacity and the indexer clustering configuration13
- Existence of premium apps: This is a relevant factor because some premium apps, such as Splunk Enterprise Security and Splunk IT Service Intelligence, have additional requirements and recommendations for the Splunk environment. For example, Splunk Enterprise Security requires a dedicated search head cluster and a minimum of 12 CPU cores per search head. Splunk IT Service Intelligence requires a minimum of 16 CPU cores and 64 GB of RAM per search head45
References:
1: Splunk Validated Architectures 2: Search head capacity planning 3: Indexer capacity planning 4: Splunk Enterprise Security Hardware and Software Requirements 5: [Splunk IT Service Intelligence Hardware and Software Requirements]
A monitored log file is changing on the forwarder. However, Splunk searches are not finding any new data that has been added. What are possible causes? (select all that apply)
Options:
An admin ran splunk clean eventdata -index
An admin has removed the Splunk fishbucket on the forwarder.
The last 256 bytes of the monitored file are not changing.
The first 256 bytes of the monitored file are not changing.
Answer:
B, CExplanation:
A monitored log file is changing on the forwarder, but Splunk searches are not finding any new data that has been added. This could be caused by two possible reasons: B. An admin has removed the Splunk fishbucket on the forwarder. C. The last 256 bytes of the monitored file are not changing. Option B is correct because the Splunk fishbucket is a directory that stores information about the files that have been monitored by Splunk, such as the file name, size, modification time, and CRC checksum. If an admin removes the fishbucket, Splunk will lose track of the files that have been previously indexed and will not index any new data from those files. Option C is correct because Splunk uses the CRC checksum of the last 256 bytes of a monitored file to determine if the file has changed since the last time it was read. If the last 256 bytes of the file are not changing, Splunk will assume that the file is unchanged and will not index any new data from it. Option A is incorrect because running the splunk clean eventdata -index
1: 2:
A multi-site indexer cluster can be configured using which of the following? (Select all that apply.)
Options:
Via Splunk Web.
Directly edit SPLUNK_HOME/etc./system/local/server.conf
Run a Splunk edit cluster-config command from the CLI.
Directly edit SPLUNK_HOME/etc/system/default/server.conf
Answer:
B, CExplanation:
A multi-site indexer cluster can be configured by directly editing SPLUNK_HOME/etc/system/local/server.conf or running a splunk edit cluster-config command from the CLI. These methods allow the administrator to specify the site attribute for each indexer node and the site_replication_factor and site_search_factor for the cluster. Configuring a multi-site indexer cluster via Splunk Web or directly editing SPLUNK_HOME/etc/system/default/server.conf are not supported methods. For more information, see Configure the indexer cluster with server.conf in the Splunk documentation.
In search head clustering, which of the following methods can you use to transfer captaincy to a different member? (Select all that apply.)
Options:
Use the Monitoring Console.
Use the Search Head Clustering settings menu from Splunk Web on any member.
Run the splunk transfer shcluster-captain command from the current captain.
Run the splunk transfer shcluster-captain command from the member you would like to become the captain.
Answer:
B, DExplanation:
In search head clustering, there are two methods to transfer captaincy to a different member. One method is to use the Search Head Clustering settings menu from Splunk Web on any member. This method allows the user to select a specific member to become the new captain, or to let Splunk choose the best candidate. The other method is to run the splunk transfer shcluster-captain command from the member that the user wants to become the new captain. This method requires the user to know the name of the target member and to have access to the CLI of that member. Using the Monitoring Console is not a method to transfer captaincy, because the Monitoring Console does not have the option to change the captain. Running the splunk transfer shcluster-captain command from the current captain is not a method to transfer captaincy, because this command will fail with an error message
New data has been added to a monitor input file. However, searches only show older data.
Which splunkd. log channel would help troubleshoot this issue?
Options:
Modularlnputs
TailingProcessor
ChunkedLBProcessor
ArchiveProcessor
Answer:
BExplanation:
The TailingProcessor channel in the splunkd.log file would help troubleshoot this issue, because it contains information about the files that Splunk monitors and indexes, such as the file path, size, modification time, and CRC checksum. It also logs any errors or warnings that occur during the file monitoring process, such as permission issues, file rotation, or file truncation. The TailingProcessor channel can help identify if Splunk is reading the new data from the monitor input file or not, and what might be causing the problem. Option B is the correct answer. Option A is incorrect because the ModularInputs channel logs information about the modular inputs that Splunk uses to collect data from external sources, such as scripts, APIs, or custom applications. It does not log information about the monitor input file. Option C is incorrect because the ChunkedLBProcessor channel logs information about the load balancing process that Splunk uses to distribute data among multiple indexers. It does not log information about the monitor input file. Option D is incorrect because the ArchiveProcessor channel logs information about the archive process that Splunk uses to move data from the hot/warm buckets to the cold/frozen buckets. It does not log information about the monitor input file12
1: 2:
Why should intermediate forwarders be avoided when possible?
Options:
To minimize license usage and cost.
To decrease mean time between failures.
Because intermediate forwarders cannot be managed by a deployment server.
To eliminate potential performance bottlenecks.
Answer:
DExplanation:
Intermediate forwarders are forwarders that receive data from other forwarders and then send that data to indexers. They can be useful in some scenarios, such as when network bandwidth or security constraints prevent direct forwarding to indexers, or when data needs to be routed, cloned, or modified in transit. However, intermediate forwarders also introduce additional complexity and overhead to the data pipeline, which can affect the performance and reliability of data ingestion. Therefore, intermediate forwarders should be avoided when possible, and used only when there is a clear benefit or requirement for them. Some of the drawbacks of intermediate forwarders are:
- They increase the number of hops and connections in the data flow, which can introduce latency and increase the risk of data loss or corruption.
- They consume more resources on the hosts where they run, such as CPU, memory, disk, and network bandwidth, which can affect the performance of other applications or processes on those hosts.
- They require additional configuration and maintenance, such as setting up inputs, outputs, load balancing, security, monitoring, and troubleshooting.
- They can create data duplication or inconsistency if they are not configured properly, such as when using cloning or routing rules.
Some of the references that support this answer are:
- Configure an intermediate forwarder, which states: “Intermediate forwarding is where a forwarder receives data from one or more forwarders and then sends that data on to another indexer. This kind of setup is useful when, for example, you have many hosts in different geographical regions and you want to send data from those forwarders to a central host in that region before forwarding the data to an indexer. All forwarder types can act as an intermediate forwarder. However, this adds complexity to your deployment and can affect performance, so use it only when necessary.”
- Intermediate data routing using universal and heavy forwarders, which states: “This document outlines a variety of Splunk options for routing data that address both technical and business requirements. Overall benefits Using splunkd intermediate data routing offers the following overall benefits: … The routing strategies described in this document enable flexibility for reliably processing data at scale. Intermediate routing enables better security in event-level data as well as in transit. The following is a list of use cases and enablers for splunkd intermediate data routing: … Limitations splunkd intermediate data routing has the following limitations: … Increased complexity and resource consumption. splunkd intermediate data routing adds complexity to the data pipeline and consumes resources on the hosts where it runs. This can affect the performance and reliability of data ingestion and other applications or processes on those hosts. Therefore, intermediate routing should be avoided when possible, and used only when there is a clear benefit or requirement for it.”
- Use forwarders to get data into Splunk Enterprise, which states: “The forwarders take the Apache data and send it to your Splunk Enterprise deployment for indexing, which consolidates, stores, and makes the data available for searching. Because of their reduced resource footprint, forwarders have a minimal performance impact on the Apache servers. … Note: You can also configure a forwarder to send data to another forwarder, which then sends the data to the indexer. This is called intermediate forwarding. However, this adds complexity to your deployment and can affect performance, so use it only when necessary.”
Which Splunk internal index contains license-related events?
Options:
_audit
_license
_internal
_introspection
Answer:
CExplanation:
The _internal index contains license-related events, such as the license usage, the license quota, the license pool, the license stack, and the license violations. These events are logged by the license manager in the license_usage.log file, which is part of the _internal index. The _audit index contains audit events, such as user actions, configuration changes, and search activity. These events are logged by the audit trail in the audit.log file, which is part of the _audit index. The _license index does not exist in Splunk, as the license-related events are stored in the _internal index. The _introspection index contains platform instrumentation data, such as the resource usage, the disk objects, the search activity, and the data ingestion. These data are logged by the introspection generator in various log files, such as resource_usage.log, disk_objects.log, search_activity.log, and data_ingestion.log, which are part of the _introspection index. For more information, see About Splunk Enterprise logging and [About the _internal index] in the Splunk documentation.
Which search head cluster component is responsible for pushing knowledge bundles to search peers, replicating configuration changes to search head cluster members, and scheduling jobs across the search head cluster?
Options:
Master
Captain
Deployer
Deployment server
Answer:
BExplanation:
The captain is the search head cluster component that is responsible for pushing knowledge bundles to search peers, replicating configuration changes to search head cluster members, and scheduling jobs across the search head cluster. The captain is elected from among the search head cluster members and performs these tasks in addition to serving search requests. The master is the indexer cluster component that is responsible for managing the replication and availability of data across the peer nodes. The deployer is the standalone instance that is responsible for distributing apps and other configurations to the search head cluster members. The deployment server is the instance that is responsible for distributing apps and other configurations to the deployment clients, such as forwarders
Which of the following can a Splunk diag contain?
Options:
Search history, Splunk users and their roles, running processes, indexed data
Server specs, current open connections, internal Splunk log files, index listings
KV store listings, internal Splunk log files, search peer bundles listings, indexed data
Splunk platform configuration details, Splunk users and their roles, current open connections, index listings
Answer:
BExplanation:
The following artifacts are included in a Splunk diag file:
- Server specs. These are the specifications of the server that Splunk runs on, such as the CPU model, the memory size, the disk space, and the network interface. These specs can help understand the Splunk hardware requirements and performance.
- Current open connections. These are the connections that Splunk has established with other Splunk instances or external sources, such as forwarders, indexers, search heads, license masters, deployment servers, and data inputs. These connections can help understand the Splunk network topology and communication.
- Internal Splunk log files. These are the log files that Splunk generates to record its own activities, such as splunkd.log, metrics.log, audit.log, and others. These logs can help troubleshoot Splunk issues and monitor Splunk performance.
- Index listings. These are the listings of the indexes that Splunk has created and configured, such as the index name, the index location, the index size, and the index attributes. These listings can help understand the Splunk data management and retention. The following artifacts are not included in a Splunk diag file:
- Search history. This is the history of the searches that Splunk has executed, such as the search query, the search time, the search results, and the search user. This history is not part of the Splunk diag file, but it can be accessed from the Splunk Web interface or the audit.log file.
- Splunk users and their roles. These are the users that Splunk has created and assigned roles to, such as the user name, the user password, the user role, and the user capabilities. These users and roles are not part of the Splunk diag file, but they can be accessed from the Splunk Web interface or the authentication.conf and authorize.conf files.
- KV store listings. These are the listings of the KV store collections and documents that Splunk has created and stored, such as the collection name, the collection schema, the document ID, and the document fields. These listings are not part of the Splunk diag file, but they can be accessed from the Splunk Web interface or the mongod.log file.
- Indexed data. These are the data that Splunk indexes and makes searchable, such as the rawdata and the tsidx files. These data are not part of the Splunk diag file, as they may contain sensitive or confidential information. For more information, see Generate a diagnostic snapshot of your Splunk Enterprise deployment in the Splunk documentation.
When using ingest-based licensing, what Splunk role requires the license manager to scale?
Options:
Search peers
Search heads
There are no roles that require the license manager to scale
Deployment clients
Answer:
CExplanation:
When using ingest-based licensing, there are no Splunk roles that require the license manager to scale, because the license manager does not need to handle any additional load or complexity. Ingest-based licensing is a new licensing model that allows customers to pay for the data they ingest into Splunk, regardless of the data source, volume, or use case. Ingest-based licensing simplifies the licensing process and eliminates the need for license pools, license stacks, license slaves, and license warnings. The license manager is still responsible for enforcing the license quota and generating license usage reports, but it does not need to communicate with any other Splunk instances or monitor their license usage. Therefore, option C is the correct answer. Option A is incorrect because search peers are indexers that participate in a distributed search. They do not affect the license manager’s scalability, because they do not report their license usage to the license manager. Option B is incorrect because search heads are Splunk instances that coordinate searches across multiple indexers. They do not affect the license manager’s scalability, because they do not report their license usage to the license manager. Option D is incorrect because deployment clients are Splunk instances that receive configuration updates and apps from a deployment server. They do not affect the license manager’s scalability, because they do not report their license usage to the license manager12
1: 2:
Which of the following tasks should the architect perform when building a deployment plan? (Select all that apply.)
Options:
Use case checklist.
Install Splunk apps.
Inventory data sources.
Review network topology.
Answer:
A, C, DExplanation:
When building a deployment plan, the architect should perform the following tasks:
- Use case checklist. A use case checklist is a document that lists the use cases that the deployment will support, along with the data sources, the data volume, the data retention, the data model, the dashboards, the reports, the alerts, and the roles and permissions for each use case. A use case checklist helps to define the scope and the functionality of the deployment, and to identify the dependencies and the requirements for each use case1
- Inventory data sources. An inventory of data sources is a document that lists the data sources that the deployment will ingest, along with the data type, the data format, the data location, the data collection method, the data volume, the data frequency, and the data owner for each data source. An inventory of data sources helps to determine the data ingestion strategy, the data parsing and enrichment, the data storage and retention, and the data security and compliance for the deployment1
- Review network topology. A review of network topology is a process that examines the network infrastructure and the network connectivity of the deployment, along with the network bandwidth, the network latency, the network security, and the network monitoring for the deployment. A review of network topology helps to optimize the network performance and reliability, and to identify the network risks and mitigations for the deployment1
Installing Splunk apps is not a task that the architect should perform when building a deployment plan, as it is a task that the administrator should perform when implementing the deployment plan. Installing Splunk apps is a technical activity that requires access to the Splunk instances and the Splunk configurations, which are not available at the planning stage
Which instance can not share functionality with the deployer?
Options:
Search head cluster member
License master
Master node
Monitoring Console (MC)
Answer:
BExplanation:
- The deployer is a Splunk Enterprise instance that distributes apps and other configurations to the members of a search head cluster1.
- The deployer cannot share functionality with any other Splunk Enterprise instance, including the license master, the master node, or the monitoring console2.
- However, the search head cluster members can share functionality with the master node and the monitoring console, as long as they are not designated as the captain of the cluster3.
- Therefore, the correct answer is B. License master, as it is the only instance that cannot share functionality with the deployer under any circumstances.
References: 1: About the deployer 2: Deployer system requirements 3: Search head cluster architecture
A customer plans to ingest 600 GB of data per day into Splunk. They will have six concurrent users, and they also want high data availability and high search performance. The customer is concerned about cost and wants to spend the minimum amount on the hardware for Splunk. How many indexers are recommended for this deployment?
Options:
Two indexers not in a cluster, assuming users run many long searches.
Three indexers not in a cluster, assuming a long data retention period.
Two indexers clustered, assuming high availability is the greatest priority.
Two indexers clustered, assuming a high volume of saved/scheduled searches.
Answer:
CExplanation:
Two indexers clustered is the recommended deployment for a customer who plans to ingest 600 GB of data per day into Splunk, has six concurrent users, and wants high data availability and high search performance. This deployment will provide enough indexing capacity and search concurrency for the customer’s needs, while also ensuring data replication and searchability across the cluster. The customer can also save on the hardware cost by using only two indexers. Two indexers not in a cluster will not provide high data availability, as there is no data replication or failover. Three indexers not in a cluster will provide more indexing capacity and search concurrency, but also more hardware cost and no data availability. The customer’s data retention period, number of long searches, or volume of saved/scheduled searches are not relevant for determining the number of indexers. For more information, see [Reference hardware] and [About indexer clusters and index replication] in the Splunk documentation.
Which of the following strongly impacts storage sizing requirements for Enterprise Security?
Options:
The number of scheduled (correlation) searches.
The number of Splunk users configured.
The number of source types used in the environment.
The number of Data Models accelerated.
Answer:
DExplanation:
Data Model acceleration is a feature that enables faster searches over large data sets by summarizing the raw data into a more efficient format. Data Model acceleration consumes additional disk space, as it stores both the raw data and the summarized data. The amount of disk space required depends on the size and complexity of the Data Model, the retention period of the summarized data, and the compression ratio of the data. According to the Splunk Enterprise Security Planning and Installation Manual, Data Model acceleration is one of the factors that strongly impacts storage sizing requirements for Enterprise Security. The other factors are the volume and type of data sources, the retention policy of the data, and the replication factor and search factor of the index cluster. The number of scheduled (correlation) searches, the number of Splunk users configured, and the number of source types used in the environment are not directly related to storage sizing requirements for Enterprise Security1
1:
Which of the following are possible causes of a crash in Splunk? (select all that apply)
Options:
Incorrect ulimit settings.
Insufficient disk IOPS.
Insufficient memory.
Running out of disk space.
Answer:
A, B, C, DExplanation:
All of the options are possible causes of a crash in Splunk. According to the Splunk documentation1, incorrect ulimit settings can lead to file descriptor exhaustion, which can cause Splunk to crash or hang. Insufficient disk IOPS can also cause Splunk to crash or become unresponsive, as Splunk relies heavily on disk performance2. Insufficient memory can cause Splunk to run out of memory and crash, especially when running complex searches or handling large volumes of data3. Running out of disk space can cause Splunk to stop indexing data and crash, as Splunk needs enough disk space to store its data and logs4.
1: Configure ulimit settings for Splunk Enterprise 2: Troubleshoot Splunk performance issues 3: Troubleshoot memory usage 4: Troubleshoot disk space issues
Which of the following are client filters available in serverclass.conf? (Select all that apply.)
Options:
DNS name.
IP address.
Splunk server role.
Platform (machine type).
Answer:
A, B, DExplanation:
The client filters available in serverclass.conf are DNS name, IP address, and platform (machine type). These filters allow the administrator to specify which forwarders belong to a server class and receive the apps and configurations from the deployment server. The Splunk server role is not a valid client filter in serverclass.conf, as it is not a property of the forwarder. For more information, see [Use forwarder management filters] in the Splunk documentation.
A new Splunk customer is using syslog to collect data from their network devices on port 514. What is the best practice for ingesting this data into Splunk?
Options:
Configure syslog to send the data to multiple Splunk indexers.
Use a Splunk indexer to collect a network input on port 514 directly.
Use a Splunk forwarder to collect the input on port 514 and forward the data.
Configure syslog to write logs and use a Splunk forwarder to collect the logs.
Answer:
DExplanation:
The best practice for ingesting syslog data from network devices on port 514 into Splunk is to configure syslog to write logs and use a Splunk forwarder to collect the logs. This practice will ensure that the data is reliably collected and forwarded to Splunk, without losing any data or overloading the Splunk indexer. Configuring syslog to send the data to multiple Splunk indexers will not guarantee data reliability, as syslog is a UDP protocol that does not provide acknowledgment or delivery confirmation. Using a Splunk indexer to collect a network input on port 514 directly will not provide data reliability or load balancing, as the indexer may not be able to handle the incoming data volume or distribute it to other indexers. Using a Splunk forwarder to collect the input on port 514 and forward the data will not provide data reliability, as the forwarder may not be able to receive the data from syslog or buffer it in case of network issues. For more information, see [Get data from TCP and UDP ports] and [Best practices for syslog data] in the Splunk documentation.
When using the props.conf LINE_BREAKER attribute to delimit multi-line events, the SHOULD_LINEMERGE attribute should be set to what?
Options:
Auto
None
True
False
Answer:
DExplanation:
When using the props.conf LINE_BREAKER attribute to delimit multi-line events, the SHOULD_LINEMERGE attribute should be set to false. This tells Splunk not to merge events that have been broken by the LINE_BREAKER. Setting the SHOULD_LINEMERGE attribute to true, auto, or none will cause Splunk to ignore the LINE_BREAKER and merge events based on other criteria. For more information, see Configure event line breaking in the Splunk documentation.
A three-node search head cluster is skipping a large number of searches across time. What should be done to increase scheduled search capacity on the search head cluster?
Options:
Create a job server on the cluster.
Add another search head to the cluster.
server.conf captain_is_adhoc_searchhead = true.
Change limits.conf value for max_searches_per_cpu to a higher value.
Answer:
DExplanation:
Changing the limits.conf value for max_searches_per_cpu to a higher value is the best option to increase scheduled search capacity on the search head cluster when a large number of searches are skipped across time. This value determines how many concurrent scheduled searches can run on each CPU core of the search head. Increasing this value will allow more scheduled searches to run at the same time, which will reduce the number of skipped searches. Creating a job server on the cluster, running the server.conf captain_is_adhoc_searchhead = true command, or adding another search head to the cluster are not the best options to increase scheduled search capacity on the search head cluster. For more information, see [Configure limits.conf] in the Splunk documentation.
Which of the following configuration attributes must be set in server, conf on the cluster manager in a single-site indexer cluster?
Options:
master_uri
site
replication_factor
site_replication_factor
Answer:
AExplanation:
The correct configuration attribute to set in server.conf on the cluster manager in a single-site indexer cluster is master_uri. This attribute specifies the URI of the cluster manager, which is required for the peer nodes and search heads to communicate with it1. The other attributes are not required for a single-site indexer cluster, but they are used for a multisite indexer cluster. The site attribute defines the site name for each node in a multisite indexer cluster2. The replication_factor attribute defines the number of copies of each bucket to maintain across the entire multisite indexer cluster3. The site_replication_factor attribute defines the number of copies of each bucket to maintain across each site in a multisite indexer cluster4. Therefore, option A is the correct answer, and options B, C, and D are incorrect.
1: Configure the cluster manager 2: Configure the site attribute 3: Configure the replication factor 4: Configure the site replication factor
In a four site indexer cluster, which configuration stores two searchable copies at the origin site, one searchable copy at site2, and a total of four searchable copies?
Options:
site_search_factor = origin:2, site1:2, total:4
site_search_factor = origin:2, site2:1, total:4
site_replication_factor = origin:2, site1:2, total:4
site_replication_factor = origin:2, site2:1, total:4
Answer:
BExplanation:
In a four site indexer cluster, the configuration that stores two searchable copies at the origin site, one searchable copy at site2, and a total of four searchable copies is site_search_factor = origin:2, site2:1, total:4. This configuration tells the cluster to maintain two copies of searchable data at the site where the data originates, one copy of searchable data at site2, and a total of four copies of searchable data across all sites. The site_search_factor determines how many copies of searchable data are maintained by the cluster for each site. The site_replication_factor determines how many copies of raw data are maintained by the cluster for each site. For more information, see Configure multisite indexer clusters with server.conf in the Splunk documentation.
To improve Splunk performance, parallelIngestionPipelines setting can be adjusted on which of the following components in the Splunk architecture? (Select all that apply.)
Options:
Indexers
Forwarders
Search head
Cluster master
Answer:
A, BExplanation:
The parallelIngestionPipelines setting can be adjusted on the indexers and forwarders to improve Splunk performance. The parallelIngestionPipelines setting determines how many concurrent data pipelines are used to process the incoming data. Increasing the parallelIngestionPipelines setting can improve the data ingestion and indexing throughput, especially for high-volume data sources. The parallelIngestionPipelines setting can be adjusted on the indexers and forwarders by editing the limits.conf file. The parallelIngestionPipelines setting cannot be adjusted on the search head or the cluster master, because they are not involved in the data ingestion and indexing process.
If .delta replication fails during knowledge bundle replication, what is the fall-back method for Splunk?
Options:
.Restart splunkd.
.delta replication.
.bundle replication.
Restart mongod.
Answer:
CExplanation:
This is the fall-back method for Splunk if .delta replication fails during knowledge bundle replication. Knowledge bundle replication is the process of distributing the knowledge objects, such as lookups, macros, and field extractions, from the search head cluster to the indexer cluster1. Splunk uses two methods of knowledge bundle replication: .delta replication and .bundle replication1. .Delta replication is the default and preferred method, as it only replicates the changes or updates to the knowledge objects, which reduces the network traffic and disk space usage1. However, if .delta replication fails for some reason, such as corrupted files or network errors, Splunk automatically switches to .bundle replication, which replicates the entire knowledge bundle, regardless of the changes or updates1. This ensures that the knowledge objects are always synchronized between the search head cluster and the indexer cluster, but it also consumes more network bandwidth and disk space1. The other options are not valid fall-back methods for Splunk. Option A, restarting splunkd, is not a method of knowledge bundle replication, but a way to restart the Splunk daemon on a node2. This may or may not fix the .delta replication failure, but it does not guarantee the synchronization of the knowledge objects. Option B, .delta replication, is not a fall-back method, but the primary method of knowledge bundle replication, which is assumed to have failed in the question1. Option D, restarting mongod, is not a method of knowledge bundle replication, but a way to restart the MongoDB daemon on a node3. This is not related to the knowledge bundle replication, but to the KV store replication, which is a different process3. Therefore, option C is the correct answer, and options A, B, and D are incorrect.
1: How knowledge bundle replication works 2: Start and stop Splunk Enterprise 3: Restart the KV store
Which index-time props.conf attributes impact indexing performance? (Select all that apply.)
Options:
REPORT
LINE_BREAKER
ANNOTATE_PUNCT
SHOULD_LINEMERGE
Answer:
B, DExplanation:
The index-time props.conf attributes that impact indexing performance are LINE_BREAKER and SHOULD_LINEMERGE. These attributes determine how Splunk breaks the incoming data into events and whether it merges multiple events into one. These operations can affect the indexing speed and the disk space consumption. The REPORT attribute does not impact indexing performance, as it is used to apply transforms at search time. The ANNOTATE_PUNCT attribute does not impact indexing performance, as it is used to add punctuation metadata to events at search time. For more information, see [About props.conf and transforms.conf] in the Splunk documentation.
Of the following types of files within an index bucket, which file type may consume the most disk?
Options:
Rawdata
Bloom filter
Metadata (.data)
Inverted index (.tsidx)
Answer:
AExplanation:
Of the following types of files within an index bucket, the rawdata file type may consume the most disk. The rawdata file type contains the compressed and encrypted raw data that Splunk has ingested. The rawdata file type is usually the largest file type in a bucket, because it stores the original data without any filtering or extraction. The bloom filter file type contains a probabilistic data structure that is used to determine if a bucket contains events that match a given search. The bloom filter file type is usually very small, because it only stores a bit array of hashes. The metadata (.data) file type contains information about the bucket properties, such as the earliest and latest event timestamps, the number of events, and the size of the bucket. The metadata file type is also usually very small, because it only stores a few lines of text. The inverted index (.tsidx) file type contains the time-series index that maps the timestamps and event IDs of the raw data. The inverted index file type can vary in size depending on the number and frequency of events, but it is usually smaller than the rawdata file type
Where in the Job Inspector can details be found to help determine where performance is affected?
Options:
Search Job Properties > runDuration
Search Job Properties > runtime
Job Details Dashboard > Total Events Matched
Execution Costs > Components
Answer:
DExplanation:
This is where in the Job Inspector details can be found to help determine where performance is affected, as it shows the time and resources spent by each component of the search, such as commands, subsearches, lookups, and post-processing1. The Execution Costs > Components section can help identify the most expensive or inefficient parts of the search, and suggest ways to optimize or improve the search performance1. The other options are not as useful as the Execution Costs > Components section for finding performance issues. Option A, Search Job Properties > runDuration, shows the total time, in seconds, that the search took to run2. This can indicate the overall performance of the search, but it does not provide any details on the specific components or factors that affected the performance. Option B, Search Job Properties > runtime, shows the time, in seconds, that the search took to run on the search head2. This can indicate the performance of the search head, but it does not account for the time spent on the indexers or the network. Option C, Job Details Dashboard > Total Events Matched, shows the number of events that matched the search criteria3. This can indicate the size and scope of the search, but it does not provide any information on the performance or efficiency of the search. Therefore, option D is the correct answer, and options A, B, and C are incorrect.
1: Execution Costs > Components 2: Search Job Properties 3: Job Details Dashboard
How does the average run time of all searches relate to the available CPU cores on the indexers?
Options:
Average run time is independent of the number of CPU cores on the indexers.
Average run time decreases as the number of CPU cores on the indexers decreases.
Average run time increases as the number of CPU cores on the indexers decreases.
Average run time increases as the number of CPU cores on the indexers increases.
Answer:
CExplanation:
The average run time of all searches increases as the number of CPU cores on the indexers decreases. The CPU cores are the processing units that execute the instructions and calculations for the data. The number of CPU cores on the indexers affects the search performance, because the indexers are responsible for retrieving and filtering the data from the indexes. The more CPU cores the indexers have, the faster they can process the data and return the results. The less CPU cores the indexers have, the slower they can process the data and return the results. Therefore, the average run time of all searches is inversely proportional to the number of CPU cores on the indexers. The average run time of all searches is not independent of the number of CPU cores on the indexers, because the CPU cores are an important factor for the search performance. The average run time of all searches does not decrease as the number of CPU cores on the indexers decreases, because this would imply that the search performance improves with less CPU cores, which is not true. The average run time of all searches does not increase as the number of CPU cores on the indexers increases, because this would imply that the search performance worsens with more CPU cores, which is not true
When adding or decommissioning a member from a Search Head Cluster (SHC), what is the proper order of operations?
Options:
1. Delete Splunk Enterprise, if it exists.2. Install and initialize the instance.3. Join the SHC.
1. Install and initialize the instance.2. Delete Splunk Enterprise, if it exists.3. Join the SHC.
1. Initialize cluster rebalance operation.2. Remove master node from cluster.3. Trigger replication.
1. Trigger replication.2. Remove master node from cluster.3. Initialize cluster rebalance operation.
Answer:
AExplanation:
When adding or decommissioning a member from a Search Head Cluster (SHC), the proper order of operations is:
- Delete Splunk Enterprise, if it exists.
- Install and initialize the instance.
- Join the SHC.
This order of operations ensures that the member has a clean and consistent Splunk installation before joining the SHC. Deleting Splunk Enterprise removes any existing configurations and data from the instance. Installing and initializing the instance sets up the Splunk software and the required roles and settings for the SHC. Joining the SHC adds the instance to the cluster and synchronizes the configurations and apps with the other members. The other order of operations are not correct, because they either skip a step or perform the steps in the wrong order.
When Splunk is installed, where are the internal indexes stored by default?
Options:
SPLUNK_HOME/bin
SPLUNK_HOME/var/lib
SPLUNK_HOME/var/run
SPLUNK_HOME/etc/system/default
Answer:
BExplanation:
Splunk internal indexes are the indexes that store Splunk’s own data, such as internal logs, metrics, audit events, and configuration snapshots. By default, Splunk internal indexes are stored in the SPLUNK_HOME/var/lib/splunk directory, along with other user-defined indexes. The SPLUNK_HOME/bin directory contains the Splunk executable files and scripts. The SPLUNK_HOME/var/run directory contains the Splunk process ID files and lock files. The SPLUNK_HOME/etc/system/default directory contains the default Splunk configuration files.
Which search will show all deployment client messages from the client (UF)?
Options:
index=_audit component=DC* host=
index=_audit component=DC* host=
index=_internal component= DC* host=
index=_internal component=DS* host=
Answer:
CExplanation:
The index=_internal component=DC* host=
Which of the following statements describe licensing in a clustered Splunk deployment? (Select all that apply.)
Options:
Free licenses do not support clustering.
Replicated data does not count against licensing.
Each cluster member requires its own clustering license.
Cluster members must share the same license pool and license master.
Answer:
A, BExplanation:
The following statements describe licensing in a clustered Splunk deployment: Free licenses do not support clustering, and replicated data does not count against licensing. Free licenses are limited to 500 MB of daily indexing volume and do not allow distributed searching or clustering. To enable clustering, a license with a higher volume limit and distributed features is required. Replicated data is data that is copied from one peer node to another for the purpose of high availability and load balancing. Replicated data does not count against licensing, because it is not new data that is ingested by Splunk. Only the original data that is indexed by the peer nodes counts against licensing. Each cluster member does not require its own clustering license, because clustering licenses are shared among the cluster members. Cluster members must share the same license pool and license master, because the license master is responsible for distributing licenses to the cluster members and enforcing the license limits
Which of the following commands is used to clear the KV store?
Options:
splunk clean kvstore
splunk clear kvstore
splunk delete kvstore
splunk reinitialize kvstore
Answer:
AExplanation:
The splunk clean kvstore command is used to clear the KV store. This command will delete all the collections and documents in the KV store and reset it to an empty state. This command can be useful for troubleshooting KV store issues or resetting the KV store data. The splunk clear kvstore, splunk delete kvstore, and splunk reinitialize kvstore commands are not valid Splunk commands. For more information, see Use the CLI to manage the KV store in the Splunk documentation.
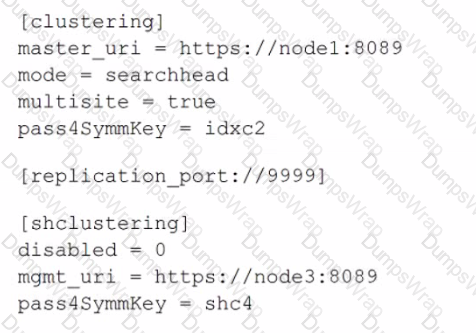
A search head cluster member contains the following in its server .conf. What is the Splunk server name of this member?
Options:
node1
shc4
idxc2
node3
Answer:
DExplanation:
The Splunk server name of the member can typically be determined by the serverName attribute in the server.conf file, which is not explicitly shown in the provided snippet. However, based on the provided configuration snippet, we can infer that this search head cluster member is configured to communicate with a cluster master (master_uri) located at node1 and a management node (mgmt_uri) located at node3. The serverName is not the same as the master_uri or mgmt_uri; these URIs indicate the location of the master and management nodes that this member interacts with.
Since the serverName is not provided in the snippet, one would typically look for a setting under the [general] stanza in server.conf. However, given the options and the common naming conventions in a Splunk environment, node3 would be a reasonable guess for the server name of this member, since it is indicated as the management URI within the [shclustering] stanza, which suggests it might be the name or address of the server in question.
For accurate identification, you would need to access the full server.conf file or the Splunk Web on the search head cluster member and look under Settings > Server settings > General settings to find the actual serverName. Reference for these details would be found in the Splunk documentation regarding the configuration files, particularly server.conf.
